
اسپارک دارای دو کتابخانه برای یادگیری ماشین با APIهای مجزا اما الگوریتم های مشابه است. این مولفههای اسپارک توانایی استفاده مقیاس پذیر از الگوریتمهای یادگیری را به توسعهدهندگان و تحلیلگران داده میدهد. در این مقاله ابتدا نگاهی به تعریف یادگیری ماشین و انواع آن و مسائل کاربردی مطرح در این حوزه خواهیم داشت و در انتها APIهای یادگیری ماشین اسپارک را معرفی خواهیم کرد.
یادگیری ماشین و علوم کامپیوتر
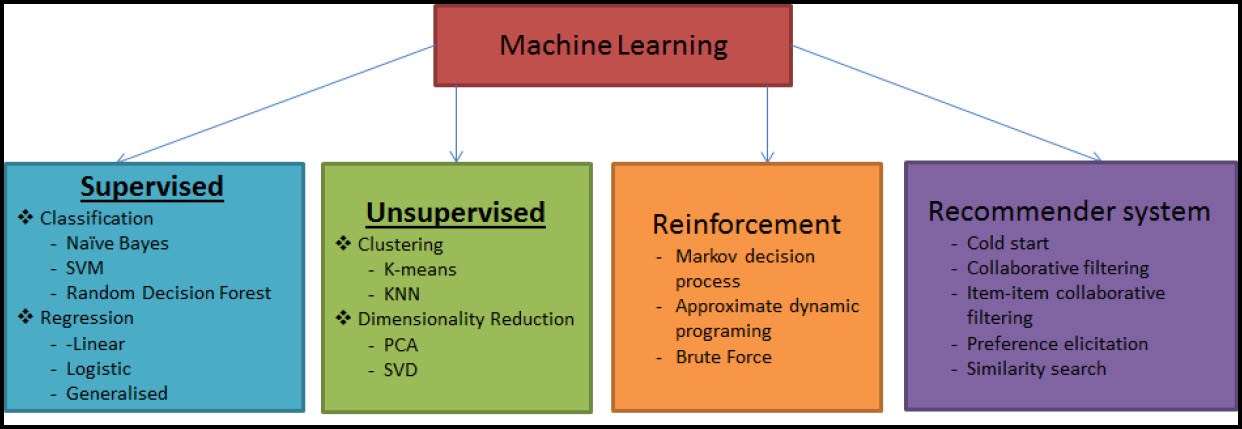
یادگیری ماشین شاخهای از علوم کامپیوتر است که به طراحی الگوریتمهایی میپردازد که از تجارب و گذشته خود یاد میگیرد و با استفاده از مطالعه تشخیص الگوها[1] و نظریه یادگیری محاسباتی[2] در هوش مصنوعی تکامل یافته است. سالها قبل برای اولین بار آلن تورینگ این مسئله را مطرح کرد، که آیا ماشین میتواند تفکر کند؟ میتوان گفت، دلایل خوبی وجود دارد که بتوان باور داشت یک ماشین با پیچیدگی کافی میتواند یک روز آزمون تورینگ[3] را پشت سر بگذراند. اما، ماشینها حداقل میتوانند یاد بگیرند. در سال 1959 میلادی، آرتور ساموئل اولین فردی بود که، واژه یادگیری ماشین را به عنوان شاخهای از علوم، که به کامپیوترها توانایی یادگیری بدون برنامه نویسی صریح میبخشد، به کار برد. از میان وظایف معمول یادگیری ماشین میتوان به یادگیری مفاهیم[4]، مدلسازی پیشبینی[5]، دستهبندی[6]، رگرسیون[7]، خوشهبندی[8]، کاهش ابعاد[9]، سیستم توصیهگر[10]، یادگیری عمیق[11] و یافتن الگوهای کاربردی در مجموعه عظیمی از دادهها اشاره کرد.
هدف نهایی پیشبرد یادگیری به نحوی است که خودکار صورت گیرد، در نتیجه دیگر به تعامل انسان نیازی نباشد، یا سطح تعامل انسان تا حد امکان کاهش یابد. با اینکه یادگیری ماشین گاهی با کشف دانش و دادهکاوی[12] (KDDM) تلفیق میشود، اما زیرشاخه آن بیشتر بر روی تحلیل اکتشافی دادهها[13] تمرکز دارد و با عنوان یادگیری بدونناظر[14] شناخته میشود – مانند خوشهبندی، تشخیص ناهنجاری[15]، شبکههای مصنوعی عصبی[16] (ANN) و غیره.
دیگر روشهای یادگیری ماشین شامل یادگیری باناظر[17] بوده، که الگوریتم یادگیری، دادههای آموزشی را تحلیل میکند و یک تابع خروجی تولید میکند که از طریق آن میتوان مثالهای جدید را پیشبینی کرد؛ دستهبندی و رگرسیون دو نمونه معمول از یادگیری باناظر هستند. روش دیگر یادگیری ماشین، یادگیری تقویتی[18] است که از روانشناسی رفتارگرا[19] الهام گرفته است، که معمولاً با چگونگی اجرای اعمال یک عامل نرمافزاری[20] در یک محیط جدید، با بیشینهسازی تابع پاداش[21]، سروکار دارد. برنامهنویسی پویا[22] و عامل هوشمند[23] دو مثال از یادگیری تقویتی هستند.
کاربردهای معمول یادگیری ماشین را میتوان به گستردهای از کاربردهای اکتشافات دانش علمی و کاربردهای تجاری تقسیم کرد، که از رباتیک یا تعامل انسان و کامپیوتر[24] (HCI) تا فیلتر ضداسپم و سیستمهای توصیهگر را شامل میشود.
یادگیری ماشین در علوم آمار و علوم تحلیل داده
یادگیری ماشین به شناسایی و ایجاد الگوریتمهایی میپردازد که میتوانند از تجارب یاد گرفته و پیشبینیهای هدفمندی بر روی داده داشته باشند. این الگوریتمها برای پیشبینیها و تصمیمات مبتنی بر داده بر اساس ساخت یک مدل از روی مجموعه دادههای آموزشی عمل میکنند، در حالیکه این روش از دنبال کردن دستورعملهای یک برنامه ایستا سریعتر است. یادگیری ماشین همچنین رابطه نزدیکی با آمار محاسباتی[25] دارد و گاهی با آن همپوشانی دارد. از سوی دیگر، آمار محاسباتی شاخهای کاربردی از علوم آمار است که به پیشبینی با رویکردی محاسباتی تمرکز دارد. همچنین، پیوند محکمی با بهینهسازی ریاضی دارد، که روشها و وظایف محاسباتی را به همراه حوزههای تئوری و کاربردی ارائه میکند.
در علوم تحلیل داده، یادگیری ماشین روشی برای ابداع مدلها و الگوریتمهای پیچیدهای است که برای پیشبینی نتایج آتی توسعه مییابد. این مدلهای تحلیلی، به پژوهشگران، دانشمندان علوم داده، مهندسان و تحلیلگران امکان تولید نتایجی قابل اطمینان، تکرارپذیر و تجدیدپذیر را میبخشد و دستیابی به الگوهای پنهان را از طریق یادگیری روابط (تجربهها) و روند پیشین دادهها ممکن میسازد. به عنوان تعریفی از یادگیری ماشین از منظر علوم کامپیوتر، میتوان عبارت زیر را ارائه داد:
به برنامه کامپیوتری گفته میشود که از تجارب (دادهها) E با توجه به گروهی از وظایف T و معیار اندازهگیری عملکرد P یاد میگیرد، در صورتی که اگر عملکردش در وظایف T، که توسط P اندازهگیری میشود، با تجربه E بهبود یابد[26].
در نتیجه، میتوان نتیجهگیری کرد که برنامه کامپیوتری یا ماشینها میتواند:
- از دادهها و تاریخچه دادهها یاد بگیرد.
- با کسب تجربه پیشرفت کند.
- به طور تعاملی یک مدل را بهبود ببخشد تا از آن برای پیشبینی نتایج مسائل استفاده کرد.
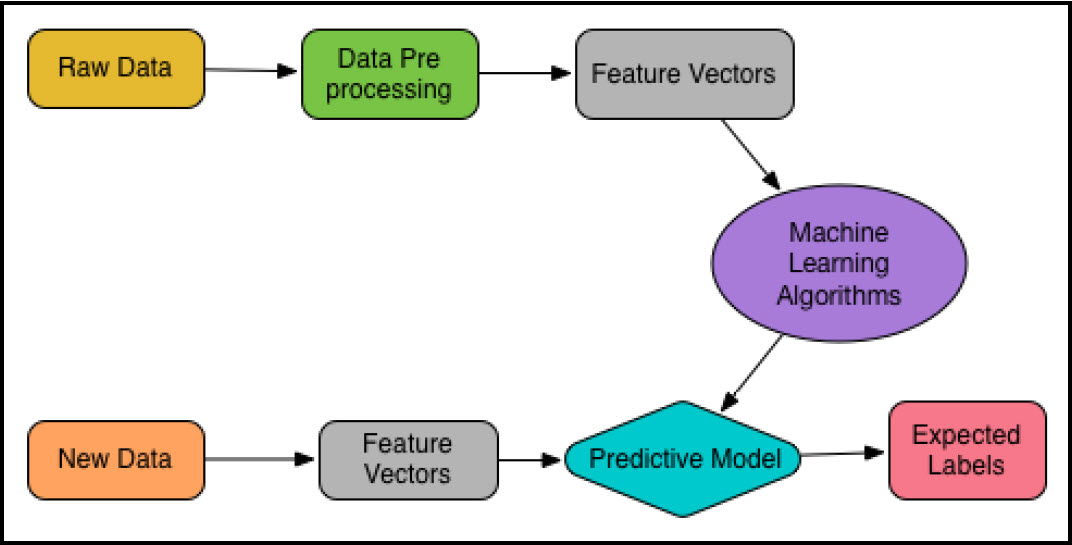
علاوهبر این، نمودار زیر میتواند به فهم روند کلی یادگیری ماشین کمک کند:
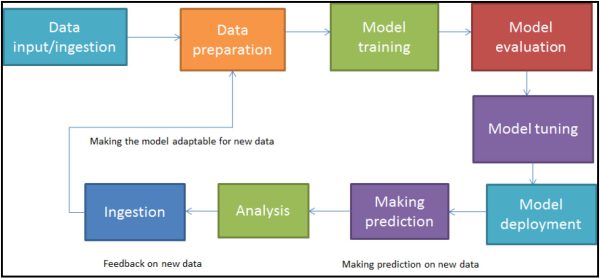
جریانکار معمول یادگیری ماشین
بهکارگیری یادگیری ماشین معمولاً شامل چندین گام، از ورودی، پردازش دادهها تا خروجی نتایج است، و میتوان آن را توسط جریانکاری نشان داده شده در شکل زیر توصیف کرد. در کاربردهای معمول یادگیری ماشین گامهای زیر طی میشود:
- داده نمونه بارگذاری میشود.
- دادهها به فرمت ورودی مناسب برای الگوریتم تجزیه میشود.
- دادهها پیشپردازش میشود و عملیات متناسبی(حذف، جایگذاری با داده پیشفرض) بر روی رکوردهای دادهای ناقص اجرا میشود.
- دادهها به دو مجموعه تقسیم میشود، یکی برای ایجاد مدل (مجموعه داده آموزشی) و یکی برای سنجش مدل (مجموعه داده تست[27] و مجموعه داده اعتبارسنجی[28])
- الگوریتم اجرا میشود تا مدل یادگیری ماشین ساخته شده و یا آموزش داده شود.
- با استفاده از دادههای آموزشی پیشبینی صورت میگیرد و نتایج مشاهده میشود.
- مدل با استفاده از دادههای تست مورد سنجش و ارزیابی قرار میگیرد یا میتوان از روش دیگری مدل را با استفاده از یک مجموعه داده سوم با تکنیک اعتبار سنجی متقابل[29] ، که به آن مجموعه دادههای اعتبارسنجی نامیده میشود، ارزیابی کرد.
- مدل برای کارایی و دقت بهتر تنظیم میشود.
- مقیاس اجرای ساخت مدل افزایش داده میشود تا در آینده بتواند برای مجموعههای کلان داده مورد استفاده قرار گیرد.
- مدل یادگیری ماشین برای فرآیند تجاری بهکار گرفته میشود.
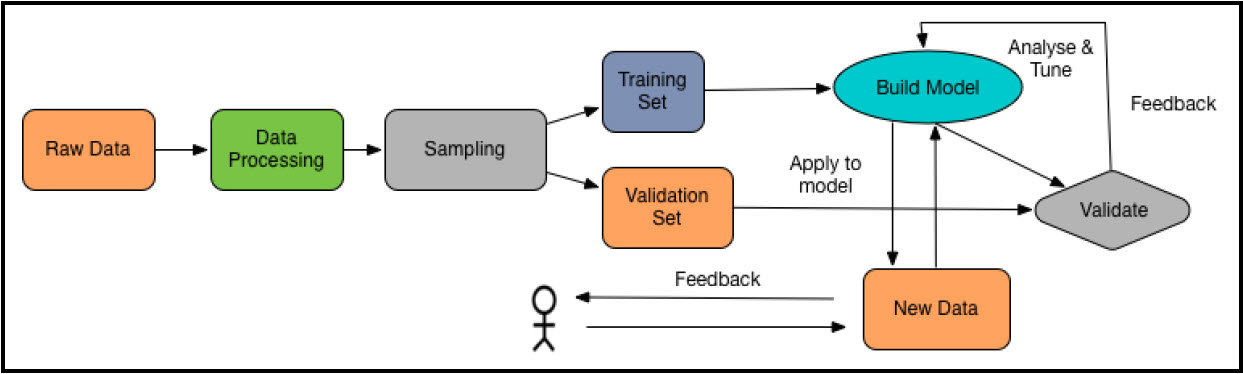
معمولاً در الگوریتمهای یادگیری ماشین روشهایی برای برخورد با میزان عدم تقارن توزیع احتمالی مجموعه دادهها دارد، که در علم آمار به آن چولگی[30] میگویند. چولگی میتواند گاهی بهطور وسیعی پراکنده باشد. در گام چهارم، مجموعه دادهها معمولاً به طور تصادفی به دو مجموعه دادههای آموزشی و دادههای تست تقسیم میشوند، که این فرآیند انتخاب نمونه[31] نامیده میشود. مجموعه دادههای آموزشی برای آموزش مدل استفاده میشود، در حالیکه دادههای تست برای ارزیابی کارایی بهتر مدل استفاده میشود. بهتر است که از مجموعه دادههای آموزشی تا حد امکان برای آموزش استفاده شود تا کارایی عمومی مدل را افزایش یاد. از سوی دیگر، از دادههای تست یکبار استفاده شود تا در حین محاسبه خطا پیشبینی و مقادیر معیارهای مرتبط دیگر از مسائل بیشبرازش[32] یا کمبرازش[33] جلوگیری شود.
بیشبرازش پارامتری آماری است و معمولاً زمانی اتفاق میافتد که تعداد ویژگیهای دادههای آموزشی زیاد باشد و باعث وابستگی مدل به دادههای آموزشی شده و برای دادههای جدید با خطای زیاد پیشبینی کند. از سوی دیگر، کمبرازش به مدلی اشاره دارد که نه میتواند دادههای آموزشی را مدل کند و نه برای دادههای جدید تعمیمپذیر است.
هر یک از این گامها از چندین روش و تکنیک تشکیل شده است، که بکارگیری از آنها مستلزم شناخت کاملتری از این گامها است.
انواع یادگیری ماشین
انواع یادگیری ماشین، براساس ماهیت بازخورد یادگیری سیستم یادگیری، معمولاً به سه دسته کلی تقسیم میشوند: یادگیری باناظر، یادگیری بدونناظر، و یادگیری تقویتی؛ این سه نوع وظایف یادگیری ماشین در شکل زیر نشان داده شده است و در بخش بعد در مورد آن صحبت میکنیم:
یادگیری باناظر
یادگیری باناظر براساس مجموعهای از مثالها آموزشی پیشبینی میکند، و هدف یادگیری قواعد عمومی است که متناسب با مثالهای دنیای واقعی، ورودیها را به خروجیهای متناسب نگاشت میکند. برای مثال، مجموعه دادههای فیلتر ایمیلهای اسپم معمولاً شامل پیغامهای اسپم و همچنین پیغامهای غیراسپم است. بنابراین، میتوان در دادههای آموزشی نشان داد که کدامیک اسپم و کدامیک غیراسپم است. باوجود این، میتوان از این اطلاعات برای آموزش مدل به منظور دستهبندی پیغامهای بررسی نشده استفاده کرد. شکل زیر نموداری از یادگیری باناظر را نشان میدهد.
به عبارت دیگر، در این مورد، مجموعهدادههای آموزشی با مقادیر مطلوب برچسبگذاری شده است و الگوریتم یادگیری باناظر به دنبال الگوهایی در این مقادیر برچسبگذاری شده است. پس از آنکه الگوریتم، الگوی مورد نیاز را پیدا کرد، این الگوها را میتوان برای پیشبینی در دادههای تست برچسبگذاری نشده استفاده کرد. این مورد از محبوبترین و پرکاربردترین انواع یادگیری ماشین است. همانطورکه در ادامه نیز بررسی میکنیم، در چهارچوب اسپارک نیز از این موضوع مستثنی نیست، و اکثر الگوریتمهای آن از روشهای یادگیری باناظر بهره میبرند.
یادگیری بدونناظر
در یادگیری بدونناظر، دادهها هیچ برچسب مرتبطی نداشته و به عبارتی، همانطور که در شکل نشان داده شده، دستههای صحیح و مشخصی در مجموعه دادههای یادگیری بدونناظر وجود ندارد. در نتیجه، دستهها باید از روی مجموعه دادههای بدونساختار استنباط شوند، به این معنی که هدف از الگوریتم یادگیری بدونناظر پیشپردازش دادهها از طریق توصیف این ساختارهاست.
برای فائق شدن بر این چالش در یادگیری بدونناظر در روشی مثل خوشهبندی معمولاً براساس معیارهای تشابه مشخصی نمونههای برچسبگذاری نشده را گروهبندی میکنند و از کشف الگوهای پنهان برای یادگیری ویژگیها[34] استفاده میشود. به بیان ساده، میتوان مدل مولدی[35] توسعه داد، تا از طریق دادهها پارامترهایی برای توصیف دادهها پیدا کنند و این عمل تکرار میشود تا نتیجه مطلوبی بدست آید.
ممکن است این سوال پیش آید، که چرا دادهها را باید برچسب گذاشت؟ آیا نمیتوان دادهها را با نظم فعلی، که هر داده منحصر به فرد شمرده میشود، در نظر داشت؟ به عبارتی با اندکی نظارت ممکن است از دادهها به هر نتیجهای رسید! پس چرا باید دادههای بدون برچسب را نیز در نظر داشت؟
موضوعات عمیقتری در این رابطه وجود دارد. مثلاً، بیشتر تغییرات در دادهها معمولاً از پدیدههایی منجر میشود که نامرتبط با برچسبگذاری مطلوب ما هستند. مثالی واقعی از این موضوع Gmail است که ایمیلها را با استفاده از روشهای یادگیری باناظر به اسپم و غیر آن دستهبندی میکند، در حالی که ممکن است دادهها از پارامترهای معنایی (سمانتیکی) برای توصیف خود استفاده کند، در حالی که آنچه برای ما اهمیت دارد پارامترهای نحوی آن است.
یادگیری تقویتی
یادگیری تقویتی روشی است که مدل از مجموعهای از اعمال و رفتارها یاد میگیرد. پیچیدگی مجموعه دادهها و یا پیچیدگی نمونه برای موفقیت یادگیری تابع هدف در یادگیری تقویتی اهمیت زیادی دارد. هدف نهایی در این روش، بیشنیه کردن تابع پاداش در تعامل با یک محیط خارجی، مطابق آنچه که در شکل زیر نشان داده شده، میباشد. برای ساده کردن نحوه بیشینهسازی تابع پاداش میتوان از جریمهکردن اعمال بد، یا پاداشدهی به اعمال خوب استفاده کرد.
برای حصول بیشترین پاداش، الگوریتم را باید مرتبا با این استراتژی که ماشین یا عامل نرمافزاری از رفتار خود یاد میگیرد، اصلاح کرد. مدل یادگیری ماشین میتواند این رفتارها را به یکباره فراگیرد، یا خود را با گذر زمان تطبیق دهد:
رباتیک مثال رایجی از یادگیری تقویتی است؛ الگوریتم باید رفتار بعدی ربات را بر اساس مجموعهای از مقادیر سنسورها انتخاب کند. همچنین، برای کاربردهای اینترنت اشیا، که برنامه با یک محیط پویا تعامل میکند، مناسب است. از مثال دیگر میتوان به بازی Flappy bird اشاره کرد، که خود بازی، بازی خود را یاد گرفته است.
سیستمهای توصیهگر
سیستمهای توصیهگر از کاربردهای در حال گسترش هستند که زیرمجموعهای از سیستمهای پالایش اطلاعات[36] به شمار میروند و برای پیشبینی امتیازدهی یا انتخابهای مورد پسند کاربران در ارائه کالا یا سرویسی به وی بکار میروند. ایده سیستمهای توصیهگر در سالهای اخیر بسیار رواج یافته و در کاربردهای متفاوتی به کار رفته است. محبوبترین کاربرد آنها برای توصیه محصولات (برای مثال، فیلم، موزیک، کتاب، مقالات پژوهشی، اخبار، جستجوها، تگهای شبکههای اجتماعی و غیره) است. سیستمهای توصیهگر را معمولاً به چهار دسته تقسیم میکنند:
- سیستمهای پالایش مشارکتی[37]، که پسند کاربران را در نظر گرفته و به کاربران دیگر براساس تشابهات الگوی رفتاری پیشنهاد میدهد.
- سیستمهای مبتنی بر محتوا[38]، که از یادگیری ماشین باناظر استفاده میکند تا کالاهای جذاب و غیرجذاب برای کاربران را دستهبندی کند.
- سیستمهای توصیهگر ترکیبی[39] که رویکرد جدیدی در تحقیقات هستند (که در آن، سیستمهای پالایش مشارکتی و مبتنی بر محتوا ترکیب میشود). نتفلیکس مثال خوبی برای چنین سیستمهای توصیهگر است که از ماشینهای بولتزمن محدود[40] (RBM) و شکلی از الگوریتم تجزیه ماتریس[41] برای پایگاهدادههای عظیم داده فیلم مانند IMDB استفاده میکند. به چنین پیشنهاداتی ،که فیلمها یا سریالهایی را با مقایسه شباهتهای کاربران در مشاهده و جستوجو پیشنهاد میدهد، پیشبینی امتیازدهی مینامند.
- سیستمهای دانش محور[42]، که از دانشی که از کاربر و محصولات دارد، استفاده میکند تا با بکارگیری از درخت ادراک[43]، سیستمهای پشتیبانی تصمیم[44] و استدلال مبتنی بر مورد[45]، استدلال کند که چه چیزی نیازهای کاربر را برآورده میکند.
یادگیری نیمهنظارتی
در میان سیستمهای باناظر و بدونناظر، جایگاهی برای یادگیری نیمهنظارتی وجود دارد، که در آن مدل یادگیری ماشین، سیگنالهای آموزشی ناکاملی دریافت میکند. از منظر آماری، مدل یادگیری ماشین مجموعهای از دادههای آموزشی دریافت میکند، که فاقد تعدادی از خروجیها است. یادگیری نیمهنظارتی کموبیش مبتنی بر فرض است و معمولاً برای مجموعه دادههای برچسبگذاری نشده از سه نوع الگوریتم مبتنی بر فرض به عنوان الگوریتمهای یادگیری استفاده میکند: فرض همواری[46]، فرض خوشه و فرض منیفلد[47].
به عبارت دیگر، سیستمهای نیمهنظارتی را میتوان به عنوان روش باناظر ضعیف یا خودراهانداز[48] برای بهرهوری از ارزش مثالهای برچسبگذاری نشده، در نظر گرفت، تا یادگیری را برای مجموعه کمی از دادههای برچسبگذاری شده بهبود بخشد.
مسائل کاربردی یادگیری ماشین
حال شاید این سوال مطرح باشد که معنای حقیقی یادگیری ماشین چیست؟ تا به اینجا، تعاریف مرسومی درباره این عبارت دیدیم. با این حال، یادگیری ماشین با مسئلهای که حل میکند تعریف میشود. در این بخش، با تاکید بر روی انواع یادگیری ماشین، چند مثال شناختهشده و متداول از آنها در دنیای واقعی را ارائه میکنیم. دستههای معمول شامل دستهبندی، خوشهبندی، استخراج قواعد و رگرسیون است، که در ادامه بحث خواهند شد.
دستههای یادگیری ماشین
دستههای ذکر شده در بالا، مسائل استانداردی است که در زندگی روزمره معمولاً از روشهای یادگیری ماشین برای حل آنها استفاده میشود. اما، دانستن دستههای یادگیری ماشین به تنهایی کافی نیست. ما همچنین باید بدانیم چه نوع مسائلی را ماشینها یاد میگیرند، زیرا مسائلی هستند که به سادگی قابل حل هستند و با کمک مدل یادگیری ماشین قابل یادگیری نیستند.
زمانی یک مسئله، مسئله یادگیری ماشین در نظر گرفته میشود که درباره یک مسئله تصمیمگیری فکر کنیم، که باید از روی دادهها مدلسازی شود و میتوان آن را به صورت یک مسئله یادگیری ماشین تعریف کرد. به طور کلی میتوان تصور کرد که که یک مسئله قابل حل با الگوریتمهای یادگیری ماشین از دو بخش اصلی تشکیل میشود. اول دادهها، که مشاهدات در یک مسئله را نشان میدهند، و دوم معیارهای کمی از کیفیت راهحل موجود. پس از آنکه مسئله را به عنوان یک مسئله یادگیری ماشین شناسایی کردید، باید درباره انواع مسائلی که با یادگیری ماشین به سادگی قابل فرموله کردن هستند، یا نوع نتایجی که کاربر به دنبال آن است، یا انواع الزاماتی که باید برآورده شوند، فکر کنید. همانطور که پیشتر گفته شد، دستههای معمول یادگیری ماشین به این شرح هستند: دستهبندی، خوشهبندی، رگرسیون، و استخراج قواعد. در ادامه مروری اجمالی بر هر کدام از دستهها ارائه میدهیم.
دستهبندی و خوشهبندی
در روش دستهبندی، دادههای آموزشی برچسبگذاری شده هستند، به این معنی که در حال حاضر دستههایی به آنها تخصیص داده شده است. برای مثال، تشخیص اسپم و غیراسپم یک ایمیل، یا تشخیص اعداد از صفر تا نه. اما، در این روش اگر مجموعه دادههایی که براساس آن تصمیمات اصلی گرفته میشود یا مدلسازی صورت گیرد برچسبگذاری نشده باشد، باید به صورت دستی یا الگوریتمی برچسبهای جدیدی تعریف شوند. این کار ممکن است مشکل باشد، اما در غیر این صورت، تشخیص تفاوتها و شباهتها بین گروههای مختلف ممکن است از لحاظ محاسباتی سختتر باشد.
از سویدیگر، خوشهبندی با دادههایی سروکار دارد که برچسبگذاری نشده یا غیر قابل برچسبگذاری است. اگرچه میتوان تشابهات را طبق معیارهای طبیعی ساختارهای داده موجود گروهبندی کرد. مرتبسازی تصاویر افراد براساس چهره و بدون داشتن نام اشخاص یکی از مثالهای این روش است.
استخراج قواعد و رگرسیون
برای یک مجموعه داده موجود، میتوان با استفاده از مقدم و تالی، قواعد گزارهای به صورت {اگر…آنگاه} ایجاد کرد تا رفتار عامل یادگیری ماشین را توصیف کنند و از نظر آماری روابط معنادار بین ویژگیهای داده را کشف کند. به این نوع از روش تولید قواعد، استخراج قواعد میگویند.
کاوش قواعد انجمنی بین آیتمها در تراکنشهای پایگاهدادهها در یک کسبوکار میتواند مثالی از استخراج قواعد باشد. بیانی ساده و کاربردی از این مثال، کشف رابطه یا وابستگی بین خرید یک کفش و گوشی موبایل از یک فروشگاه است، که به نوعی نشاندهنده امیال و موقعیت کاربران است. با این حال، در این روش ممکن است حالتی پیش آید که پیشبینیهای خارج از قواعد یا دادهها را الزاماً به صورت مستقیم شامل نباشد.
اما در روش رگرسیون دادهها با مقادیر حقیقی پیوسته برچسبگذاری شدهاند. به بیان دقیقتر ، دادهها مقداری اعشاری به جای برچسب داده در دستههای مختلف هستند . دادههای سری زمانی مثل قیمت سهام یا ارز که نسبت به زمان متغیر است از جمله مثالهای این روش هستند. برای این نوع دادهها، وظیفه رگرسیون پیشبینی برای داده جدید و پیشبینی نشده با استفاده از روشهای مدلسازی رگرسیونی است.
مسائل رایج یادگیری ماشین
تعداد زیادی از مثالهای کاربردی یادگیری ماشین را میتوانید در زندگی روزمره بیابید، آنها با کمک الگوریتمها و تکنیکها بخش مشکل مسائل موجود را حل میکنند. اغلب ما از نرمافزارهای تحت وب یا دسکتاپ برای سادهتر کردن مشکلات استفاده میکنیم بدون اینکه بدانیم از چه تکنیکهایی در پسزمینه استفاده شده است. بسیاری از آنها با بکارگیری گسترده الگوریتمهای یادگیری ماشین زندگی ما را سادهتر کردهاند. در ادامه به تعدادی از این مثالها اشاره میشود:
- تشخیص و فیلتر ایمیل اسپم: تشخیص ایمیلهای اسپم از ایمیلهای غیراسپم (که معمولاً ham نامیده میشوند) از کاربردهای یادگیری ماشین است. ایمیلهای غیراسپم باید تشخیص داده شوند تا در داخل اینباکس قرار بگیرند، و ایمیلهای اسپم به پوشه مربوط به اسپم انتقال یابد و یا آنها را به صورت دائم از حسابکاربری حذف کند.
- تشخیص ناهنجاری یا تشخیص داده خارج از محدوده[49]: در تشخیص ناهنجاری، با شناسایی موارد، رخدادها یا مشاهداتی سروکار داریم که غیر منتظره و غیر سازگار با الگوی مورد انتظار مجموعه داده است؛ به عبارت دیگر، تشخیص الگوهای غیر قابل اعتماد. مثال رایج آن تشخیص ناهنجاری در شبکه است.
- کشف تقلب در کارت اعتباری: امروزه تقلب در کارت اعتباری بسیار رایج است. دزدی اطلاعات مرتبط با کارت اعتباری از طریق فروش آنلاین و استفاده از آن در راههای غیرقانونی در بسیاری از کشورها اتفاق میافتد. تصور کنید که تراکنشهای پایگاهداده یک کاربر در یک ماه بهخصوص را در اختیار دارید. با توسعه یک برنامه یادگیری ماشین میتوان تراکنشهایی که توسط کاربر انجام میشود را از آنهایی که توسط دیگران به صورت غیرقانونی صورت میگیرد، تشخیص دهد.
- تشخیص صدا: تشخیص صدا و تبدیل آن به فرمان نوشتاری و سپس انجام یک عمل که توسط عامل هوشمند انجام میگیرد. کاربرد رایج آن در Siri اپل، S-voice در سامسونگ، Echo ساخته آمازون و Cortana مایکروسافت است. مثال دیگر آن قفلگشایی تلفنهمراه هوشمند با استفاده از قابلیت تشخیص صدا است.
- تشخیص رقم/کاراکتر: تصور کنید که یک کدپستی دستنویس یا یک آدرس یا یک پیغام در داخل یا روی یک پاکت نامه نوشتهاید، وظیفه این سیستم تشخیص و دستهبندی ارقام یا کاراکترها برای هر کاراکتر نوشته شده با دستخط افراد مختلف است. کاربرد مناسب یادگیری ماشین در این زمینه میتواند به خواندن و فهم کدپستی یا کاراکترهای نوشته شده و مرتبسازی محتوای پاکتها براساس موقعیت جغرافیایی، یا به بیان فنیتر به بخشبندی تصاویر، کمک کند.
- اینترنت اشیاء: تحلیل دادههای سنسورها در مقیاس بزرگ برای پیشبینی و دستهبنده دادههای زمان واقع و جریانی میتواند از کاربردهای مهم یادگیری ماشین باشد. برای مثال، نظارت بر سطح آب، دمای اتاق و کنترل لوازم خانگی و غیره.
- تشخیص چهره: شناسایی تصاویر افراد از صدها و هزاران عکس، که شبیه فرد معینی است. یک مدل بهینه یادگیری ماشین، در این مورد، میتواند تصاویر را بر اساس اشخاص مرتب سازد.
- پیشنهاد محصول: با داشتن تاریخچه خرید مشتری در یک فهرست بزرگی از موجودی محصولات، به کمک سیستم یادگیری ماشین، میتوان کالاهایی را که مشتری احتمالاً به خرید آنها علاقهمند است، شناسایی کرد . شرکتهای پیشگام در تجارت و تکنولوژی مانند آمازون، فیسبوک و گوگل پلاس از این قابلیتهای پیشنهاددهی برای کاربران خود استفاده میکنند.
- معامله سهام: با داشتن قیمت حال و تاریخچه قیمت بازار سهام، با کمک سیستم یادگیری ماشین میتوان به سطحی از پیشبینی تغییرات سهامهایی که باید خرید و فروش شود تا به سود منجر شود، دست پیدا کرد.
در ادامه مثالهایی از یادگیری ماشین ارائه میکنیم که در حال ظهور بوده و در صدر پژوهشهای امروزی هستند:
- حفظ حریم خصوصی در داده کاوی: کاوش قواعد خرید مشتریان از الگوهای تکرارشونده حداکثری[50] و قواعد انجمنی از پایگاه دادههای کسبوکارهای خرده فروش برای افزایش فروش در آینده.
- سیستمهای توصیهگر: سیستمهای توصیهگر مبتنی بر جریان دادههای کلیک با استفاده از قواعد انجمنی دادهکاوی.
- متنکاوی: برای مثال، کنترل سرقت ادبی در یک مجموعه متنی.
- تجزیه و تحلیل احساسات: بسیاری از تصمیمها در کسبوکار و شرکتهای فناوری براساس نظرات دیگران گرفته میشود، و این جایگاه خوبی برای استفاده از یادگیری ماشین است.
- درک گفتار: با صحبت کردن یک کاربر، هدف شناسایی درخواست کاربر است. این مسئله میتواند به برنامه اجازه فهم و اقدام در راستای برآورد درخواست کاربر دهد. برای مثال Siri آیفون در وضعیت میتینگ این قابلیت را به کار گرفته است.
تعدادی از این مسائل از سختترین چالشها در هوش مصنوعی، پردازش زبانهای طبیعی و بینایی ماشین هستند و میتوانند توسط الگوریتمهای یادگیری ماشین حل شوند.
رابطهای کاربردی برنامهنویسی اسپارک برای یادگیری ماشین در کلان داده
در این بخش، دو مفهوم کلیدی معرفی شده توسط کتابخانههای یادگیری ماشین اسپارک (اسپارک MLlib و اسپارک ML)، و الگوریتمهای پرکاربردی که در راستای روشهای یادگیری باناظر و بدونناظر پیادهسازی شدهاند، را معرفی میکنیم.
کتابخانههای یادگیری ماشین در اسپارک
پیش از اسپارک، معمولاً برای مدلهای یادگیری ماشین در کلانداده از زبانهای آماری مانند R، STATA و SAS استفاده میشد. سپس، مهندسان داده این مدلها را مجدداً، برای مثال در جاوا، برای بکارگیری در هادوپ پیادهسازی کردند. اما، این نوع از جریانکار، فاقد بازده، مقیاسپذیری، توانپردازشی مناسب، و دقت بوده و زمان اجرا را طولانی میکند.
با استفاده از اسپارک، همان مدلهای یادگیری ماشین میتوانند ساخته شوند و به کار گرفته شوند، در حالی که جریانکار را بسیار کارآمد، مقاوم و سریعتر میکند و در عمل کارایی بیشتر میشود. کتابخانههای یادگیری ماشین اسپارک در دو پکیج قرار دارند: اسپارک spark.mllib) MLlib) و اسپارک spark.ml) ML) .
اسپارک MLlib
MLlib، کتابخانه مقیاسپذیر یادگیری ماشین اسپارک، که توسعهای از API هسته اسپارک است، کتابخانهای ارائه میدهد که به سادگی برای الگوریتمهای یادگیری ماشین قابل استفاده است. الگوریتمها با زبانهای جاوا، اسکالا و پایتون نوشته و پیادهسازی شدهاند. اسپارک، از نوع دادههای بردارهای محلی و ماتریسهای محلی[51] که بر روی یک ماشین ذخیره شده باشد و همچنین از ماتریسهای توزیع شده توسط یک یا چند RDD پشتیبانی میکند.
|
اسپارک MLlib |
||
|
انواع یادگیری ماشین |
گسسته |
پیوسته |
|
باناظر |
دستهبندی: |
رگرسیون: |
|
Logistic regression and regularized variants Linear SVM Naive Bayes Decision trees Random forests Gradient-boosted trees |
Linear regression and regularized variants Linear least squares Lasso and ridge regression Isotonic regression |
|
|
بدون ناظر |
خوشهبندی: |
کاهش ابعاد، تجزیه ماتریس: |
|
K-means Gaussian matrix Power iteration clustering (PIC) Latent Dirichlet Allocation (LDA) Bisecting K-means Streaming K-means |
Principal components analysis Singular value decomposition Alternate least square |
|
|
تقویتی |
ناموجود |
ناموجود |
|
سیستمهای توصیهگر |
پالایش مشارکتی: |
ناموجود |
|
Netflix recommendation |
||
جدول 1: کتابخانه اسپارک MLlib در یک نگاه
- پیوسته: پیشبینی کردن از متغیرهای پیوسته، برای مثال، پیشبینی حداکثر دما در روزهای آتی بر اساس متغیر پیوسته اندازه دما.
- گسسته: نسبت دادن برچسبهای گسسته به یک مشاهده به عنوان نتیجه یک پیشبینی، برای مثال، در پیشبینی هوا، پیشبینی میتواند روزی آفتابی، بارانی و یا برفی باشد.
قابلیتهای کتابخانه MLlib در اسپارک بیشمار است. برای مثال، الگوریتمهای پیادهسازی شده توسط اسکالا، جاوا و پایتون مقیاسپذیری بالایی دارند و از توانایی اسپارک برای مواجهه با حجم عظیمی از داده بهره میگیرند. این الگوریتمها با بکارگیری از APIهای Dataset، DataFrame، و RDD مبتنی بر گراف جهتدار غیرمدور[52] (DAG) برای پردازشهای موازی و مبتنی بر حافظه اصلی طراحی شدهاند، که میتواند تا 100 برابر نسبت به پردازش نگاشت-گاهش[53] سریعتر باشد (همچنین از عملکرد مبتنی بر دیسک نیز پشتیبانی میکند که در این شرایط نیز میتواند تا 10 برابر از پردازشهای معمول نگاشت-گاهش سریعتر باشد).
این مجموعه همچنین متمایز و گوناگون است، زیرا تمامی الگوریتمهای رایج یادگیری ماشین برای تحلیل رگرسیون، دستهبندی، خوشهبندی، سیستمهای توصیهگر، تحلیل متن، کاوش الگوهای تکرارشونده را پوشش میدهد و مشخصاً تمامی گامهای مورد نیاز برای ساخت یک نرمافزار یادگیری ماشین مقیاسپذیر را در خود دارد.
اسپارک ML
اسپارک ML مجموعه جدیدی APIهای یادگیری ماشین را به سکوی اسپارک اضافه کرده است تا کاربران بتوانند به سرعت خطلولههای[54] عملی یادگیری ماشین را بر Datasetها، پیکربندی کنند. هدف اسپارک ML ارائه مجموعهای یکدست از APIهای سطح بالا است که بر DataFrameها به جای RDDها ساخته شدهاند که به کابران اجازه ساخت و تنظیم خطلولههای عملی یادگیری ماشین را میدهند. APIهای اسپارک ML، الگوریتمهای یادگیری ماشین را استاندارد ساخته تا با ترکیب چندین الگوریتم در یک خطلوله یا جریانکار داده وظایف یادگیری را راحتتر کند.
اسپارک ML از مفهوم DataFrame (البته در جاوا کنار گذاشته شده اما هنوز در پایتون و R رابط برنامهنویسی اصلی است) استفاده میکند که در نسخۀ 1.3.0 اسپارک از اسپارک SQL به عنوان Dataset یادگیری ماشین معرفی شد. Datasetها انواع مختلفی از نوع دادههای متفاوت مانند فرمتهای CSV، Json، بردارهای ویژگی[55] و برچسبهای صحیح[56] دادهها را ذخیره میکنند. علاوهبراین، اسپارک ML برای تبدیل یک DataFrame به دیگری از Transformerها استفاده میکند، و از مفهوم Estimator استفاده میشود تا متناسب با DataFrame یک Transformer جدید تولید کند. از طرفی خطلوله میتواند چند Transformer و Estimator را تجمیع کند تا یک جریانکار داده یادگیری ماشین را شکل دهد. مفهوم parameter نیز معرفی شده است تا تمام ترانسفومرها و استیماتورها در طول توسعه برنامه یادگیری ماشین، API مشترکی برای توسعه برنامههای ML داشته باشند.
| اسپارک ML | ||
| انواع یادگیری ماشین | گسسته | پیوسته |
| باناظر | دستهبندی: | رگرسیون: |
|
Logistic regression Decision tree classifier Random forest classifier Gradient-boosted tree classifier Multilayer perception classifier One-vs-Rest classifier |
Linear regression Decision tree regression Random forest regression Gradient-boosted tree regression Survival regression |
|
| بدون ناظر | خوشهبندی: | گروههای درختی: |
|
K-means (Latent Dirichlet allocation (LDA |
Random forests Gradient-boosted Trees |
|
| تقویتی | ناموجود | ناموجود |
| سیستمهای توصیهگر | ناموجود | ناموجود |
جدول 2:کتابخانۀ اسپارک ML در یک نگاه
همانطور که در جدول بالا نشان داده شد، اسپاک ML بسیاری از الگوریتمهای دستهبندی، رگرسیون، درخت تصمیم، گروههای درختی و همچنین الگوریتمهای خوشهبندی را، به منظور توسعه خطلولههای یادگیری ماشین بر دیتافریم فراهم کرده است. الگوریتم بهینهسازی استفاده شده از پیادهسازی OWL-QN[57] میباشد، که الگوریتمی پیشرفته و توسعهای از L-BFGGS است و میتواند به صورت موثر برای منظمسازی L1 و الاستیک نت[58] بکارگرفته شود.
[1] pattern recognition
[2] computational learning theory
[3] Turing test
[4] Concept learning
[5] Predictive modeling
[6] Classification
[7] Regression
[8] Clustering
[9] Dimensionality reduction
[10] Recommender system
[11] Deep learning
[12] Knowledge Discovery and Data Mining (KDDM)
[13] Exploratory data analysis
[14] unsupervised learning
[15] anomaly detection
[16] Artificial Neural Networks (ANN)
[17] supervised learning
[18] Reinforcement learning
[19] Behaviorist psychology
[20] software agent
[21] Reward function
[22] Dynamic programming
[23] Intelligent agent
[24] Human–computer interaction
[25] computational statistics
[26] http://www.cs.cmu.edu/~tom/pubs/MachineLearning.pdf
[27] test dataset
[28] validation dataset
[29] cross-validation
[30] skewness
[31] sampling
[32] Overfitting
[33] Underfitting
[34] feature learning
[35] generative model
[36] information filtering system
[37] Collaborative filtering system
[38] Content-based systems
[39] Hybrid recommender systems
[40] Restricted Boltzmann Machines
[41] Matrix Factorization
[42] Knowledge-based systems
[43] Perception tree
[44] Decision support systems
[45] Case-based reasoning
[46] Smoothness
[47] Manifold assumption
[48] Bootstrapping
[49] Anomaly detection or outlier detection
[50] maximal frequent pattern
[51] local vectors and matrix
[52] Directed Acyclic Graph
[53] MapReduce
[54] pipelines
[55] feature vectors
[56] true labels
[57] Orthant-Wise Limited-memory Quasi-Newton
[58] Elastic Net