
آپاچی اسپارک یک سکوی پردازشی خوشهایی متن باز است و در حال حاضر یکی از پروژههای موفق در بنیاد نرمافزار آپاچی میباشد. اسپارک به وضوح از پیشروهای پردزاش کلانداده شده است و امروزه توسط شرکتهای بزرگی نظیر آمازون، IBM و یاهو مورد استفاده قرار میگیرد. در برخی از سازمانها سکوی اسپارک بروی خوشهایی با هزاران گره پردازشی در حال اجرا است. در پردازشهای زمانواقعی[1] کلان داده اسپارک در میان راهحلهای موجود میتواند به عنوان یکی از بهترین گزینهها مطرح باشد، اما در ورای آن، اسپارک همچنین به گونهایی طراحی شده است که در عین سرعت، بتواند یک چهارچوب همه منظوره برای تمام نیازهای کار با داده باشد. ما در پست “معرفی آپاچی اسپارک” به برخی از ویژگیها و خصوصیات اسپارک اشاره کردیم. در این پست قصد داریم به معرفی مولفههای اصلی اسپارک از جمله هسته اسپارک، مولفه SQL، Streaming، MLib و GraphX بپردازیم و در انتها انواع روشهای مدیریت خوشه اسپارک را معرفی کنیم.
اسپارک در مقابله با موتور پردازشی نگاشت/کاهش
از نظر سرعت، اسپارک مدل محبوب نگاشت-کاهش[2] را به منظور افزایش بازده انواع بیشتری از پردازشها از جمله پرسوجوهای تعاملی[3] و پردازشهای جریانی[4] گسترش داده است(در مقاله مدل برنامهنویسی نگاشت/کاهش میتوانید در مورد آن مطالعه کنید). سرعت در پردازش مجموعه دادههای بزرگ مهم میباشد، زیرا این امر به معنای تفاوت بین بررسی تعاملی دادهها و انتظار به مدت چند دقیقه یا چند ساعت میباشد. یکی از ویژگی های اصلی اسپارک در زمینه سرعت، توانایی اجرای پردازشها در حافظه میباشد، و نیز این سیستم بسیار پربازدهتر از مدل نگاشت-کاهش برای برنامههای پیچیدهای است که بر روی دیسک اجرا میشوند.
همهمنظوره بودن اسپارک
از نظر همه منظوره بودن، اسپارک برای پوشش گستره وسیعی از بارهای کاری[5] طراحی شده است که پیشتر نیازمند سیستمهای توزیعی مستقل بود. از این میان میتوان به پردازشهای دستهای[6]، الگوریتمهای تکرار شونده[7]، پرسوجوهای تعاملی و جریانی اشاره کرد. با پشتیبانی از این بارهای کاری در یک موتور پردازشی مشابه، اسپارک امکان ترکیب انواع مختلف پردازش را تسهیل و کم هزینه میکند که اغلب در تولید یک زنجیره تحلیل دادهها ضروری[8] میباشد. علاوه بر این، این سیستم منجر به کاهش بار مدیریتی نگهداری ابزارهای مستقل میگردد.
اسپارک به گونهای طراحی شده است که در دسترس باشد و API های سادهای را در پایتون، جاوا، اسکالا، SQL و کتابخانههای داخلی فراهم میآورد. این سیستم همچنین براحتی با اکثر ابزارهای کلان داده ترکیب میشود. بهویژه، اسپارک میتواند در خوشههای هدوپ اجرا شده و به تمام منابع داده هدوپ(سیستمفایل توزیع شده هدوپ) و یا پایگاه دادهایی نظیر Cassandra و یا Mongodb دسترسی داشته باشد.
یک استک متحد
پروژه اسپارک حاوی اجزای بسیار منسجمی میباشد. در اصل، اسپارک یک “موتور پردازشی” است که مسئولیت زمانبندی ، توزیع و کنترل برنامههایی که از تعداد زیادی وظایف پردازشی[9] در سایر ماشینهای کاری یا خوشه پردازشی تشکیل شدهاند، را بر عهده دارد. از آنجایی که بنا است موتور اصلی اسپارک سریع و چندمنظوره باشد، مولفههای پیشرفتهای را برای بارهای کاری مختلف نظیر SQL و یا یادگیری ماشین تامین میکند. این اجزا به منظور عملکردی نزدیک با یکدیگر طراحی شدهاند و به شما امکان ترکیب آنها مثل ترکیب کتابخانهها در یک پروژه نرم افزاری را میدهد.
فلسفه انسجام بسیار نزدیک این اجزا مزایای متعددی دارد. اولا، تمام کتابخانهها و اجزای سطح بالا در استک اسپارک از پیشرفتهای موجود در لایه های زیرین بهرهمند میشوند. برای مثال، زمانی که موتور مرکزی اسپارک یک بهینه سازی را می افزاید، مولفه SQL، پردازش جریانی، مولفه تحلیل گراف و کتابخانههای یادگیری ماشین نیز به طور خودکار سرعت میگیرند. ثانیا، هزینههای مربوط به اجرای یک استک از این مولفهها نیز کاهش یافته است، زیرا به جای اجرای 5-10 سیستم نرم افزاری مستقل، یک سازمان نیازمند اجرای یک استک نرمافزاری میباشد. این هزینهها شامل استقرار، نگهداری، تست، پشتیبانی و … می باشند. این امر همچنین بدین معناست که هر زمان یک جزء جدید به استک اسپارک افزوده میشود، هر سازمانی که از اسپارک استفاده میکند نیز میتواند این ابزار جدید را امتحان کند. این امر هزینه انجام نوع جدیدی از تحلیل داده از دریافت، استقرار و یادگیری یک پروژه نرم افزاری جدید برای ارتقای اسپارک را کاهش میدهد.
در نهایت، یکی از بزرگترین مزایای انسجام نزدیک اجزا، توانایی ساخت برنامههایی است که مدلهای مختلف پردازش را به طور یکپارچه ترکیب میکند. برای مثال، در اسپارک شما میتوانید برنامهای را بنویسید که از یادگیری ماشین برای دستهبندی دادهها همزمان با دریافت از منابع جریانی استفاده میکند. همچنین، تحلیلگران نیز میتوانند داده های حاصل را از طریق SQL و به طور لحظه ای پرسوجو کنند(برای مثال به منظور پیوند دادهها با فایلهای لاگ غیرساختاری). علاوه بر این، مهندسین داده و متخصصین داده باتجربه نیز میتوانند از طریق محیط تعاملی پایتون یا اسکالا به دادههای مشابه برای تحلیل هایی خاص دسترسی داشته باشند. سایر افراد نیز در برنامههای دسته ای مستقل[10] به دادهها دسترسی دارند. در این میان، تیم IT نیز باید فقط یک سیستم را نگهداری کند.
در ادامه به معرفی مختصر هر یک از اجزای اسپارک خواهیم پرداخت. این مولفهها در شکل زیر نشان داده شدهاند.
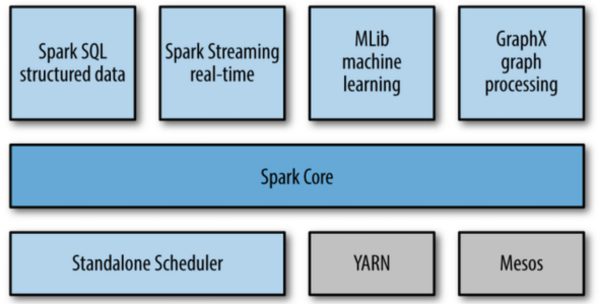
Spark Core
هسته اسپارک حاوی عملیاتهای اولیه اسپارک از جمله اجزای موردنیاز برای زمانبندی وظایف، مدیریت حافظه، مقابله با خطا، تعامل با سیستم ذخیره سازی و … می باشد. هسته اسپارک همچنین محل توسعه APIهایی میباشد که [11]RDDها را تعریف میکنند و RDDها مفهوم اصلی برنامهنویسی اسپارک میباشند. RDDها نشانگر مجموعهای از آیتمها هستند که بر روی گرههای محاسباتی متعدد توزیع شده و میتوان آنها را به صورت موازی پردازش کرد. هسته اسپارک APIهای متعددی را برای ایجاد و دستکاری این مجموعهها ارائه میدهد.
Spark SQL
اسپارک SQL چهارچوبی برای کار کردن با دادههای ساختیافته و دارای اسکیما میباشد. این سیستم پرسوجو دادهها را از طریق SQL و همچنین آپاچی هایو[12]، نوع دیگر SQL که HQL نیز نامیده میشود، امکان پذیر ساخته و از منابع داده از جمله جداول هایو، ساختار دادههای Parquet،CSV و JSON پشتیبانی میکند. علاوه بر ارائه یک رابط کاربری SQL برای اسپارک، اسپارک SQL توسعه دهندگان را قادر میسازد تا پرسوجوهای SQL را با عملیاتهای تغییر دادهها بروی RDDها که در پایتون، جاوا و اسکالا پشتیبانی میشود، ترکیب کرده و در یک برنامه پرسجوهای SQL را با تحلیلهای پیچیده منسجم کرد. این انسجام نزدیک با محیط پردازشی ارائه شده توسط اسپارک، اسپارک SQLرا از سایر ابزارهای انبار داده متن باز متمایز میکند. اسپارک SQLدر نسخه 1.0 به اسپارک افزوده شد.
Spark Streaming
مولفه پردازش دادههای جریانی اسپارک[13] یکی از اجزای اسپارک است که پردازش جریان دادهها را فراهم میآورد. از نمونههای جریان دادهها میتوان به فایل های لاگ ایجاد شده توسط سرورهای وب یا مجموعه پیامهای حاوی به روز رسانی وضعیت ارسال شده توسط کاربران یک وب سرویس و یا در شبکههای اجتماعی نظیر ارسال کردن یک پست اشاره کرد. API ،Spark Streamingهایی را برای تغییر جریانهای داده که با APIهای مربوط به RDDهای موجود در هسته اسپارک همخوانی دارد، ارائه میدهد و این امر موجب تسهیل توسعه برنامه برای توسعهدهندگان و سوییچ بین برنامههایی که دادهها را در حافظه اصلی، بر روی دیسک و یا در زمان واقعی پردازش میکنند، میشود. در معماری توسعه این APIها، به منظور برخورداری از قابلیت تحمل خطا، بهرهوری بالا و مقیاس پذیری، همانند مولفه هسته اسپارک به نکات مربوط به توسعه سیستمهای توزیع شده توجه شده است.
MLlib
اسپارک دارای کتابخانهای متشکل از APIهای یادگیری ماشین (ML) با نام MLlib میباشد. MLlib انواع مختلفی از الگوریتمهای یادگیری ماشین از جمله دستهبندی[14]، رگرسیون[15]، خوشهبندی[16] و پالایش گروهی[17] را ارائه میدهد و همچنین از قابلیتهای مثل ارزیابی مدل و ورود دادهها پشتیبانی میکند. MLlib همچنین ساختارهای سطح پایین یادگیری ماشین مثل الگوریتم بهینهسازی گرادیان نزولی را فراهم میآورد. تمام این روشها با منظور اجرا کردن این برنامهها در سطح کلاستر اسپارک طراحی شدهاند.
GraphX
GraphX یک کتابخانه برای پردازش گرافها (نظیر گراف دوستی شبکههای اجتماعی) و انجام پردازشهای موازی بروی دادههای گراف میباشد. GraphX همانند مولفههای اسپارک استریمینگ و اسپارک API ،SQLهای RDDها را توسعه داده و ما را قادر میسازد تا گرافهای جهتدار با نسبت دادن مشخصات به هر گره و یال ایجاد کنیم. GraphX همچنین عملگرهای مختلفی را برای تغییر گرافها (نظیر subgraph و mapVertices) و کتابخانهای از الگوریتمهای گراف خاص (نظیر PageRank و شمارش مثلثهای گراف) فراهم آورده است.
مدیریت خوشه اسپارک
در اصل، اسپارک برای مقیاسپذیری از یک تا چندین هزار گره پردازشی طراحی شده است. به منظور دستیابی به این امر و همچنین افزایش انعطافپذیری، اسپارک میتواند بر روی انواعی از مدیریت خوشهای از جمله Hadoop YARN، Apache Mesos، و یک مدیر خوشه ساده موجود در خود اسپارک با نام Standalone Scheduler اجرا شود. اگر شما اسپارک را بر روی تک ماشین نصب میکنید، Standalone Scheduler روش سادهای را برای آغاز کار فراهم میآورد، و اگر شما خوشه Hadoop YARN یا Mesos دارید، پشتیبانی اسپارک از این مدیریتهای خوشهای منجر میشود که برنامههای شما بر روی آنها نیز اجرا شود.
در پستهای بعدی در رابطه با ایجاد کلاستر و مدل برنامهنویسی در اسپارک صحبت خواهیم کرد.
[1] Real Time
[2] MapReduce
[3] interactive queries
[4] stream processing
[5] workloads
[6] Batch
[7] iterative algorithms
[8] production data analysis pipelines
[9] Tasks
[10] Standalone batch applications
[11] Resilient distributed datasets
[12] Hive
[13] Spark Streaming
[14] Classification
[15] Regression
[16] Clustering
[17] collaborative filtering