
این مقاله، یک روایت از تاریخچه بوجود آمدن سیستمهای تحیلی است که توسط شرکت Databricks منتشر شده است. در این متن به چالشهای روزمره سازمانها در مواجه با تجزیه و تحلیل حجم زیاد دادهها اشاره شده است که استفاده از رویکردی نظیر Lakhouse را برای سازمانها موجه و قابل تأمل میکند.
مقدمه
میتوان گفت بیشتر تحولات در طی چندین دهه رخ میدهد. تکامل به قدری آهسته اتفاق میافتد که مراحل تکامل به صورت روزانه قابل مشاهده نیستند. تماشای پیشرفت روزانه یک تکامل، چیزی شبیه به تماشای خشک شدن رنگ روی یک سطح از نظر یک تماشاگر است. با این حال، تکامل فناوری کامپیوتر با سرعتی بسیار بالا و از دهه 1960 شروع شده است.

روند تکامل تکنولوژی
روزی روزگاری، وقتی صحبت از کامپیوتر میشد، زندگی ساده بود. دادهها وارد پردازشگر شده، پردازش میشدند و سپس خارج میشدند. در ابتدا نوار کاغذی بوجود آمد. نوارهای کاغذی خودکار بود اما مقدار کمیاز دادهها را در قالب ثابت ذخیره میکرد. سپس کارتهای پانچ بوجود آمدند. یکی از مشکلات کارتهای پانچ این بود که فرمت آنها ثابت بود. حجم عظیمیاز کارتهای پانچ شده، مقادیر زیادی کاغذ مصرف میکردند و بهم ریختن دستهای از کارتها منجر به تلاش خستهکنندهای برای مرتب کردن کارتها میشد.
سپس پردازش دادههای مدرن با نوار مغناطیسی آغاز شد، که دریچه جدیدی را برای ذخیره سازی و استفاده از حجم بیشتری از دادهها در قالب ثابت باز کرد. مشکل نوار مغناطیسی این بود که برای یافتن یک رکورد خاص باید کل فایل را جستجو میکردید. با بیان متفاوت، با فایلها بروی نوار مغناطیسی، باید دادهها را به صورت متوالی جستجو کنید. و نوارهای مغناطیسی بسیار شکننده بودند، بنابراین ذخیره دادهها برای مدت طولانی بسیار چالش برانگیز بود.
پس از آن، ذخیرهسازی بروی دیسک بوجود آمد. فضای ذخیرهسازی دیسک واقعاً با ارائه دسترسی مستقیم به دادهها، گزینههای بیشتری را برای پردازش مدرن فناوری اطلاعات ایجاد کرد. با ذخیره سازی بروی دیسک، بدون دسترسی به صورت متوالی، میتوانید مستقیماً به یک رکورد خاص دسترسی داشته باشید. اگرچه در اوایل مسائل مربوط به هزینه و در دسترس بودن وجود داشت، اما ذخیرهسازی دیسک بسیار ارزان تر شد و حجم زیادی از ذخیرهسازی مبتنی بر دیسک به مرور زمان به طور گسترده در دسترس قرار گرفت.
پردازش تراکنشهای آنلاین (OLTP)
با خاصیت کارایی بالا و دسترسی مستقیم به دادهها در دیسکها، سیستمهای تراکنش آنلاین (OLTP) امکانپذیر شد. هنگامیکه سیستمهای پردازش تراکنش آنلاین در دسترس قرار گرفتند، کسبوکارها دریافتند که رایانهها میتوانند وارد ساختار اصلی تجارت شوند. اکنون میتوان سیستمهای رزرو آنلاین، سیستمهای خودپرداز بانک و موارد مشابه وجود داشته باشد. اکنون رایانهها میتوانند مستقیماً با مشتریان تعامل داشته باشند.
در ابتدای مسیر، کامپیوتر برای انجام فعالیتهای تکراری مفید بود. اما با سیستمهای پردازش تراکنش آنلاین، رایانه برای تعامل مستقیم با مشتری مفید بود. با انجام این کار، پتانسیل ارزش تجاری سیستمهای کامپیوتری به طور چشمگیری افزایش یافت.
برنامههای کامپیوتری
خیلی سریع، برنامهها مانند علفهای هرز در بهار رشد کردند. به زودی برنامههای کاربردی در همه جا وجود داشتند.
مشکل یکپارچگی دادهها
با رشد برنامهها مشکلی جدید و پیشبینی نشدهایی بوجود آمد. در روزهای اولیه، کاربر نهایی از نداشتن اطلاعات خود شکایت داشت. اما پس از غرق شدن در برنامهها، کاربر نهایی از پیدا نکردن دادههای درست شکایت میکرد. کاربر نهایی از ناتوانی در یافتن دادهها به ناتوانی در یافتن دادههای مناسب تبدیل شد. این یک تغییر تقریباً پیش پا افتاده به نظر میرسید، اما هر چیزی جز پیش پا افتاده بود.
با گسترش این برنامههای کاربردی، مشکل یکپارچگی دادهها به وجود آمد. دادههای یکسان در بسیاری از مکانها با مقادیر گاه متفاوت ظاهر میشوند. برای تصمیمگیری، کاربر نهایی باید جستجو میکرد که کدام نسخه از دادهها برای استفاده از بین بسیاری از برنامههای کاربردی موجود مناسب است. انتخابهای ضعیف کسبوکار زمانی ایجاد میشوند که کاربر نهایی نسخه مناسب دادهها را پیدا نکرده و از آن استفاده نمیکند.
چالش یافتن دادههای مناسب چالشی بود که کاربران کمیآن را درک میکردند. اما با گذشت زمان، کاربران شروع به درک پیچیدگی یافتن دادههای مناسب برای استفاده برای تصمیمگیری کردند. کارشناسان و متخصصان دریافتند که به یک رویکرد معماری متفاوتی از ساختن برنامههای کاربردی نیاز دارند. افزودن ماشینها، فناوری و مشاوران بیشتر، مسائل مربوط به یکپارچگی دادهها را نیز بدتر کرد و به بهبود آن کمکی نکرد.
افزودن تکنولوژی بیشتر، مشکلات عدم یکپارچگی دادهها را نیز به صورت اغراق آمیز بیشتر کرد
انبار دادهها
به عصر انبار داده خوش آمدید. انبار داده منجر به کپی شدن دادههای برنامههای متفاوت در یک مکان فیزیکی جداگانه شد. بنابراین، انبار داده ارائه یک راه حل معماری برای یک مشکل بوجود آمده از معماری بود.
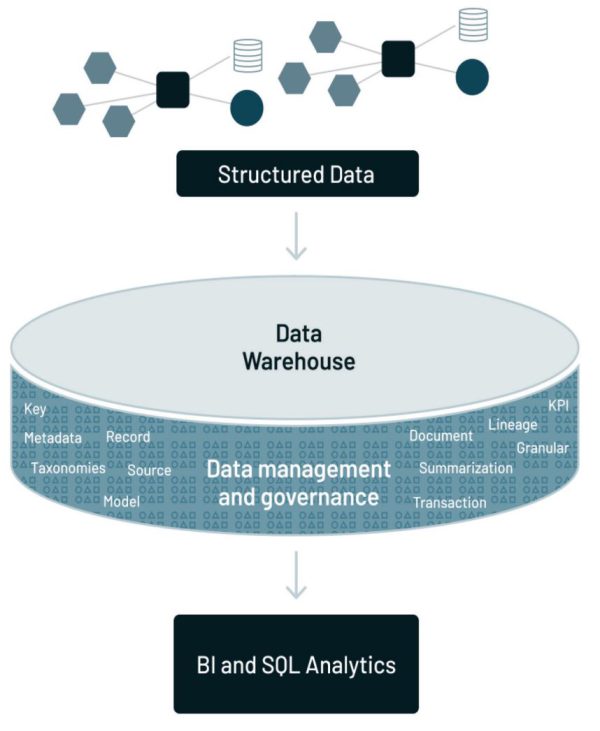
صرف یکپارچهسازی دادهها و قرار دادن آنها در یک مکان فیزیکی مجزا تنها شروع معماری بود. برای موفقیت، طراح باید یک زیرساخت کاملاً جدید در اطراف انبار دادهایجاد میکرد. زیرساختی که انبار داده را احاطه و ایجاد کرده بود، دادههای یافت شده در انبار داده را قابل استفاده و آماده برای تجزیه و تحلیل میکرد. با بیان متفاوت، به همان اندازه که انبار داده مهم بود، کاربر نهایی بدون زیرساختهای تحلیلی پوشش دهنده انبار داده، ارزش کمیدر انبار داده پیدا میکرد. زیرساختهای تحلیلی شامل:
- متاداده – راهنمایی برای اینکه چه دادههایی در کجا قرار گرفتهاند
- مدل داده – انتزاعی از دادههای موجود در انبار داده
- اصل و نسب داده(Lineage) – داستان منشأ و تبدیل دادههای موجود در انبار داده
- خلاصه سازی – شرح الگوریتمیک کارها برای ایجاد داده در انبار داده
- شاخصهای کلیدی عملکرد (KPIها) – شاخصهای کلیدی عملکرد در کجا وجود دارند
- ETL – فناوری که به دادههای برنامهها اجازه میدهد به طور خودکار به دادههای مناسب برای تحلیل کسب و کار تبدیل شوند
چالش دادههای تاریخچهایی
انبار داده مانع دیگری را برای پردازش تحلیلی دادهها برداشت. قبل از ذخیرهسازی داده، هیچ مکان مناسبی برای ذخیره دادههای قدیمیتر و بایگانیشده بهراحتی و کارآمد وجود نداشت – برای سازمانها عادی بود که یک هفته، یک ماه یا حتی یک فصل دادهها را در سیستمهای خود ذخیره کنند. اما به ندرت پیش میآمد که یک سازمان دادههای یک یا پنج ساله را ذخیره کند. اما با انباردادهها، سازمانها میتوانند ده سال یا بیشتر دادههای خود را ذخیره کنند.
توانایی ذخیره طیف طولانیتری از دادههای با ارزش زمانی، بسیار ارزشمند بود. برای مثال، زمانی که سازمانها به عادات خرید مشتری علاقهمند شدند، درک الگوهای خرید گذشته به درک الگوهای خرید فعلی و آتی کمک میکرد.
گذشته به یک پیشبینی کننده بزرگ آینده تبدیل شد
انبار دادهها، زینپس، بُعد مدت زمان بیشتر برای ذخیره سازی دادهها را به دنیای تجزیه و تحلیل دادهها اضافه کرد. اکنون دادههای تاریخی دیگر چالش پیچیدهایی نبود.
همانطور که انبارهای داده مهم و مفید هستند، در بیشتر موارد، انبارهای داده بر روی دادههای ساختار یافته و مبتنی بر تراکنش تمرکز میکنند. شایان ذکر است که بسیاری از انواع دادههای دیگر(نیمه سارختار یافته، بدون ساختار) در محیط ساختاریافته یا انبار داده در دسترس نیستند.
تکامل فناوری با ظهور دادههای ساختیافته متوقف نشد. به زودی دادههایی از منابع مختلف و متنوع ظاهر شدند. مراکز تماس، اینترنت و ماشینها و برنامههای جدیدی بودند که دادههایی نه لزوما ساختار یافته تولید میکردند. به نظر میرسید دادهها از همه جا میآمدند. تکامل محیط فراتر از دادههای ساختاری و مبتنی بر تراکنش ادامه یافت.
محدودیتهای انبارهای داده با افزایش تنوع دادهها (متن، اینترنت اشیا، تصاویر، صدا، ویدئو، حسگرهای و غیره) در شرکتها آشکار شد. علاوه بر این، ظهور یادگیری ماشینی (ML) و هوش مصنوعی (AI)، الگوریتمهای تکراری را معرفی کرد که مستلزم دسترسی مستقیم به دادهها(که بر اساس SQL نیستند) است.
تمام دادههای سازمان
به همان اندازه که انبارهای داده مهم و مفید هستند، در بیشتر موارد، انبارهای داده حول دادههای ساخت یافته متمرکز شدهاند. اما در حال حاضر، بسیاری از انواع دادههای دیگر در سازمان وجود دارد. برای اینکه ببینید چه دادههایی در یک سازمان وجود دارد، یک نمودار ساده را در نظر بگیرید.

دادههای ساختاریافته معمولاً دادههای مبتنی بر تراکنش هستند که توسط یک سازمان برای انجام فعالیتهای تجاری روزانه تولید میشوند. دادههای متنی دادههایی هستند که توسط نامهها، ایمیلها و مکالمات درون سازمان تولید میشوند. سایر دادههای بدون ساختار منابع دیگری مانند اینترنت اشیا، تصاویر، ویدئو و دادههای مبتنی بر آنالوگ دارند.
دادههای ساختار یافته
اولین نوع دادهای که ظاهر شد، دادههای ساخت یافته بود. در بیشتر موارد، دادههای ساختار یافته محصول فرعی پردازش تراکنشها بود. زمانی که تراکنش انجام میشود یک رکورد ایجاد میشود. این میتواند یک عملیات فروش، پرداخت، تماس تلفنی، فعالیت بانکی یا انواع دیگری از تراکنش باشد. هر رکورد جدید ساختاری مشابه رکورد قبلی دارد.
برای مشاهده این تشابه پردازش، سپرده گذاری در بانک را در نظر بگیرید. یکی از مشتریان بانک به سمت عابر بانک میرود و واریز پول انجام میدهد. شخص بعدی نیز یک پرداخت انجام میدهد. اگرچه شماره حساب و مبالغ سپرده متفاوت است، اما ساختار هر دو رکورد یکسان است.
“دادههای ساختاریافته” همان ساختار داده را به طور مکرر نوشته و بازنویسی میکنند
معمولاً هنگامیکه دادههای ساختار یافته داریم، رکوردهای زیادی بوجود میآید – یکی برای هر تراکنشی که رخ داده است. بنابراین، به طور طبیعی، ارزش تحلیلی بالایی بر روی دادههای ساختاریافته قرار میگیرد، حتی تنها برای همین یک دلیل کهاین دادهها به قلب یک کسب و کار بسیار نزدیک هستند.
دادههای متنی
دلیل اصلی مفید نبودن متن خام این است که متن خام نیز باید حاوی زمینه(context) باشد تا درک شود. بنابراین، صرف خواندن و تحلیل متن خام کافی نیست.
برای تجزیه و تحلیل متن باید هم متن و هم زمینه متن را درک کنیم
با این حال، ما باید دیگر جنبههای متن را در نظر بگیریم. باید در نظر بگیریم که متنها در زبانهای متفاوتی وجود دارند، مانند انگلیسی، اسپانیایی، آلمانی و غیره، همچنین برخی از متنها قابل پیشبینی هستند، اما متنهای دیگر قابل پیش بینی نیستند. تحلیل متن قابل پیشبینی با تحلیل متن غیر قابل پیشبینی بسیار متفاوت است. یکی دیگر از موانع تجزیه و تحلیل دقیق این است که یک کلمه میتواند معانی متعددی داشته باشد. کلمه “رکورد” میتواند به معنای ضبط یک آهنگ باشد. یا میتواند به معنای سرعت یک مسابقه باشد و یا موارد دیگر. و موانع دیگری که خواندن، تجزیه و تحلیل متن خام را دشوار میکند.
ETL متنی
خوشبختانه ایجاد متن در قالب ساختاریافته یک قابلیت امکانپذیر است. این فناوری با عنوان ETL متنی شناخته میشود. با ETL متنی، میتوانید متن خام را بخوانید و آن را به یک قالب پایگاه داده استاندارد تبدیل کنید و متن و زمینه را شناسایی کنید. و با انجام این کار، اکنون میتوانید شروع به ترکیب دادههای ساختار یافته و متن کنید. یا میتوانید به تنهایی یک تحلیل مستقل از متن انجام دهید.
دادههای اینترنت اشیا و آنالوگ
عملکرد یک ماشین، مانند خودرو، ساعت یا ماشینهای کارخانههای تولیدی، دادههای آنالوگ را ایجاد میکنند. تا زمانی که این دستگاهها کار میکند، دادههای متریکها را به بیرون میفرستند. متریکها ممکن است از موارد زیادی باشد – مانند دما، ترکیب شیمیایی، سرعت، زمان روز، و غیره. در واقع، دادههای آنالوگ ممکن است از متغیرهای مختلفی باشد که به طور همزمان اندازهگیری و گرفته میشوند. چشمهای الکترونیکی، مانیتورهای دما، تجهیزات ویدئویی، تله متری، تایمرها – منابع زیادی برای دادههای آنالوگ وجود دارد.
طبیعی است که نرخ دادههای آنالوگ زیاد باشد. بسته به دستگاه و پردازشی که در حال انجام است، اندازه گیری در هر ثانیه، هر ده ثانیه یا شاید هر دقیقه، امری طبیعی است. در حقیقت، بسیاری از اندازهگیریها – آنهایی که در محدوده نرمال هستند – ممکن است چندان جالب یا مفید نباشند. اما گاهی اوقات، اندازه گیری خارج از محدوده نرمال وجود دارد که در واقع بسیار جالب است. چالش در گرفتن و مدیریت دادههای آنالوگ و اینترنت اشیا در تعیین موارد زیر است:
- چه نوع دادههایی باید جمع آوری و اندازه گیری شود؟
- فرکانس گرفتن دادهها؟
- محدوده نرمال بودن؟
چالشهای دیگر شامل حجم دادههای جمعآوریشده، نیاز به تغییر گهگاهی دادهها، یافتن و حذف موارد پرت، ارتباط دادههای آنالوگ با دادههای دیگر و غیره است. به عنوان یک قاعده، دادهها در محدوده نرمال را در ذخیره سازی انبوه و دادههای خارج از محدوده نرمال را در یک ذخیره سازی جداگانه ذخیره کنید. روش دیگر برای ذخیره دادهها، ارتباط با حل مسئله است. به طور سنتی، انواع خاصی از دادهها نسبت به انواع دیگر دادهها برای حل یک مشکل مرتبطتر هستند. معمولاً سه مورد وجود دارد که توجه شخصی را که دادههای آنالوگ را تجزیه و تحلیل میکند جلب میکند:
- مقادیر خاص دادهها
- الگو دادهها در تعداد زیادی از رخدادها
- الگوهای همبستگی
انواع دیگر دادههای بدون ساختار
اکثر دادههای تولید شده توسط شرکتها امروزه تحت دادههای ساختار نیافته – تصاویر، محتوای صوتی و ویدئویی قرار میگیرند.
شما نمیتوانید این دادهها را در یک جدول پایگاه داده معمولی ذخیره کنید زیرا به طور معمول فاقد ساختار جدولی است. با توجه به حجم عظیم دادههای آنالوگ و اینترنت اشیا، ذخیره و مدیریت این مجموعه دادهها بسیار پرهزینه است. تجزیه و تحلیل دادههای بدون ساختار با رابطهای فقط SQL آسان نیست. با این حال، با ظهور فضای ذخیرهسازی اشیا ارزان در ابر، منابع پردازشی ابری الاستیک و الگوریتمهای یادگیری ماشین میتوانند مستقیماً به دادههای ساختار نیافته دسترسی داشته باشند – این امر باعث شد شرکتها شروع به بررسی پتانسیل ارزش این مجموعه از دادهها کنند. در اینجا چند مورد استفاده نوظهور برای دادههای بدون ساختار آورده شده است:
دادههای تصویری
- تجزیه و تحلیل تصویر پزشکی برای کمک به رادیولوژیستها در اسکن اشعهایکس، CT و MRI
- طبقهبندی تصویر برای هتلها و رستورانها برای طبقه بندی تصاویری از خواص و غذای آنها
- جستجوی بصری برای کشف محصول برای بهبود تجربه برای شرکتهای تجارت الکترونیک
- شناسایی برند در تصاویر رسانههای اجتماعی برای شناسایی جمعیت شناسی برای کمپینهای بازاریابی
دادههای صوتی
- رونویسی خودکار دادههای صوتی مرکز تماس برای کمک به ارائه خدمات بهتر به مشتریان
- تکنیکهای هوش مصنوعی مکالمهای برای تشخیص گفتار و برقراری ارتباط به روشی مشابه مکالمه انسانی
- هوش مصنوعی صوتی برای ترسیم علائم صوتی مختلف ماشینها در یک کارخانه تولید برای نظارت فعال بر تجهیزات
دادههای ویدیویی
- تجزیه و تحلیل ویدیوی تحلیلی در فروشگاه برای ارائه شمارش افراد، تجزیه و تحلیل صف، نقشههای حرارتی و غیره برای درک نحوه تعامل مردم با محصولات
- تجزیه و تحلیل ویدیویی برای ردیابی خودکار موجودی و همچنین شناسایی عیوب محصول در فرآیند تولید
- دادههای ویدیویی برای ارائه دادههای استفاده عمیق، به سیاستگذاران و دولتها کمک میکند تا تصمیم بگیرند چه زمانی زیرساختهای عمومی نیاز به تعمیر و نگهداری دارد
- تشخیص چهره به کارکنان مراقبتهای بهداشتی این امکان را میدهد که در صورت و زمانی که بیمار مبتلا به زوال عقل، مرکز را ترک میکند، آگاه شوند و به طور مناسب پاسخ دهند.
ارزش کسب و کار این دادهها کجاست؟
انواع مختلفی از ارزش تجاری دادهها در طبقهبندیهای مختلف وجود دارد. اول، ارزش تجاری برای فعالیتهای روزانه، دوم، ارزش تجاری استراتژیک بلند مدت و سوم، ارزش تجاری در مدیریت و بهره برداری از دستگاههای مکانیکی.
جای تعجب نیست که یک رابطه بسیار قوی بین دادههای ساختاریافته و ارزش تجاری وجود دارد. دنیای تراکنشها و دادههای ساختاریافته جایی است که سازمان تجارت روزانه خود را انجام میدهد. و همچنین یک رابطه قوی بین دادههای متنی و ارزش تجاری وجود دارد. متن ساختار اصلی تجارت است. اما نوع متفاوتی از رابطه تجاری بین دادههای آنالوگ/IoT و تجارت امروزی وجود دارد. امروزه سازمانها با دسترسی به منابع عظیم محاسبات ابری و چارچوبهای یادگیری ماشین، پتانسیل دادههای آنالوگ/IoT را درک کردهاند. به عنوان مثال، سازمانها از دادههای تصویری برای شناسایی نقصهای کیفیت در تولید، دادههای صوتی در مراکز تماس برای تجزیه و تحلیل احساسات مشتری و دادههای ویدئویی عملیات از راه دور مانند خطوط لوله نفت و گاز برای انجام تعمیرات پیشبینیکننده استفاده میکنند.
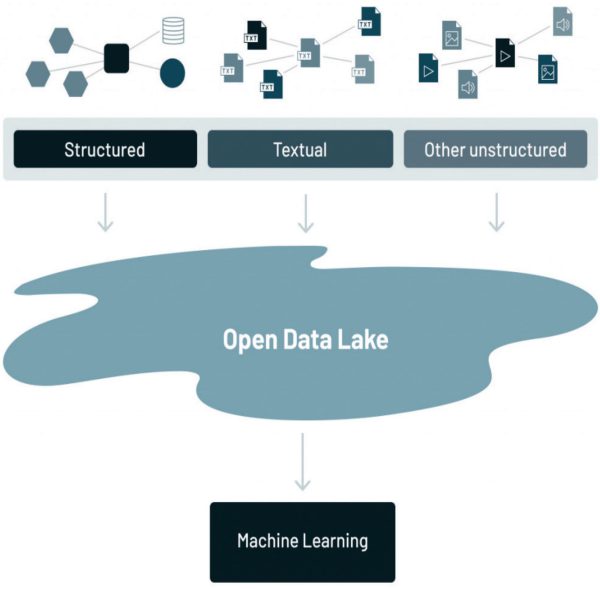
دریاچه داده
دریاچه داده ترکیبی از انواع مختلف دادههای موجود در سازمان است
اولین نوع داده در دریاچه، دادههای ساختاری است. نوع دوم دادهها، دادههای متنی هستند. و سومین نوع داده، دادههای آنالوگ/IoT است. چالشهای زیادی با دادههایی که در دریاچه داده قرار دارند وجود دارد. اما یکی از بزرگترین چالشها این است که شکل و ساختار دادههای آنالوگ/IoT با دادههای ساختار یافته کلاسیک در انبار داده بسیار متفاوت است. برای پیچیدهتر کردن مسائل، حجم دادهها در انواع مختلف دادههای موجود در دریاچه داده بسیار متفاوت است. به عنوان یک قاعده، مقدار بسیار زیادی داده در بخش آنالوگ/IoT دریاچه داده در مقایسه با حجم دادههای موجود در انواع دیگر دادهها وجود دارد. دریاچه داده جایی است که شرکتها با توجه به سیستمهای ذخیرهسازی کمهزینه آن با یک API فایل که دادهها را در قالبهای فایل عمومی و باز مانند Apache Parquet و ORC ذخیره میکند، همه دادههای خود را در آن نگهداری میکنند. همچنین استفاده از فرمتهای باز، دادههای دریاچه داده را مستقیماً برای طیف گستردهای از موتورهای تحلیلی دیگر، مانند سیستمهای یادگیری ماشینی، در دسترس قرار میدهد.
در ابتدا تصور میشد که تنها چیزی که لازم است استخراج دادهها و قرار دادن آنها در دریاچه داده است. در یک دریاچه داده، کاربر نهایی فقط میتواند شیرجه بزند و دادهها را پیدا کند و تجزیه و تحلیل کند. با این حال، سازمانها به سرعت دریافتند که استفاده از دادهها در دریاچه دادهها داستانی کاملاً متفاوت از صرف قرار دادن دادهها در دریاچه داده است. با بیان متفاوت، نیازهای کاربر نهایی با نیازهای دانشمند داده بسیار متفاوت بود.
کاربر نهایی با انواع موانع برخورد میکرد:
- دادههای مورد نیاز کجا هستند؟
- چگونه یک واحد داده با واحد داده دیگر ارتباط داشت؟
- آیا دادهها به روز هستند؟
- دادهها چقدر دقیق هستند؟
بسیاری از وعدههای دریاچههای داده به دلیل فقدان برخی از ویژگیهای زیرساختی حیاتی محقق نشدهاند: عدم پشتیبانی از تراکنشها، عدم اجرای کیفیت داده یا حاکمیت، و بهینهسازی عملکرد ضعیف. در نتیجه، بیشتر دریاچههای داده در شرکت به باتلاق داده تبدیل شده اند.
در یک باتلاق داده، دادهها فقط در جایی قرار میگیرند که کسی از آن استفاده نمیکند. در باتلاق دادهها، دادهها به مرور زمان پوسیده میشوند
چالشهای فعلی معماری داده
یک رویکرد تحلیلی رایج استفاده از سیستمهای متعدد است – یک دریاچه داده، چندین انبار داده و سایر سیستمهای تخصصی که منجر به سه مشکل رایج میشود:
اول، انتقال دادههای پرهزینه با معماری دوگانه. بیش از 90 درصد از دادههای آنالوگ/اینترنت اشیا به دلیل انعطاف پذیری دریاچه داده از دسترسی مستقیم باز به فایلها و هزینه کم آنها در ذخیره سازی است، زیرا از ذخیره سازی ارزان استفاده میکند. برای غلبه بر کمبود عملکرد و مشکلات کیفیت دریاچه داده، شرکتها از ETL (Extract/Transform/Load) برای کپی کردن زیرمجموعه کوچکی از دادهها در دریاچه داده به انبار داده پایین دستی برای مهمترین برنامههای تصمیمیار و BI استفاده میکنند. این معماری سیستم دوگانه نیاز به مهندسی مداوم برای دادههای ETL بین دریاچه و انبار داده دارد. هر مرحله ETL خطر بروز خطا یا ایجاد اشکالاتی را دارد که کیفیت دادهها را کاهش میدهد – ثابت نگه داشتن دریاچه و انبار داده دشوار و پرهزینه است.
دوم، پشتیبانی محدود برای یادگیری ماشین. علیرغم تحقیقات زیاد در مورد تلاقی ML و مدیریت دادهها، هیچ یک از سیستمهای یادگیری ماشین پیشرو، مانند TensorFlow، PyTorch و XGBoost، به خوبی در بالای انبار دادهها کار نمیکنند. برخلاف هوش تجاری (BI) که مقدار کمی داده را استخراج میکند، سیستمهای ML مجموعه دادههای بزرگ را با استفاده از کدهای غیر SQL پیچیده پردازش میکنند.
سوم، عدم باز بودن. انبارهای داده، دادهها را در قالبهای اختصاصی قفل میکنند که هزینه انتقال داده یا بار کاری به سیستمهای دیگر را افزایش میدهد. با توجه بهاینکه انبارهای داده در درجه اول دسترسی فقط SQL را ارائه میکنند، اجرای موتورهای تحلیلی دیگر مانند سیستمهای یادگیری ماشین در مقابل انبارهای داده دشوار است.
پیدایش Data Lakehouse
از باتلاق دادهها، کلاس جدیدی از معماری داده به نام داده Lakehouse پدیدار شد. Lakehouse دارای چندین جزء است:
- دادهها از محیط ساخت یافته
- دادهها از محیط متنی
- دادهها از محیط آنالوگ/IoT
- یک زیرساخت تحلیلی که امکان خواندن و درک دادهها را در Lakehouse فراهم میکند
یک طراحی سیستم باز و استاندارد شده جدید، تجزیه و تحلیل دادههای آنالوگ/اینترنت اشیا را با پیاده سازی ساختارهای داده و ویژگیهای مدیریت داده انبار داده ترکیب میکند، و این امر ار مستقیماً بر روی نوع ذخیره سازی کم هزینهای که برای دریاچههای داده استفاده میشود، امکان پذیر میکند.
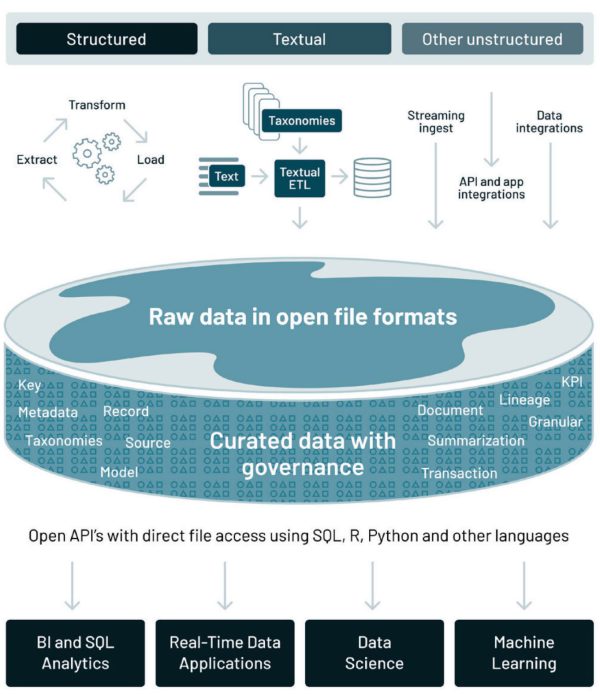
معماری Lakehouse داده، چالشهای کلیدی معماری دادههای فعلی را که در اقدام قبلی مورد بحث قرار گرفت، با ایجاد بر روی دریاچههای داده موجود، برطرف میکند
در ادامه شش مرحله برای ایجاد پشتیبانی مولفه آنالوگ/IoT در معماری Lakehouse داده آورده شده است:
1- اتخاذ رویکرد lake-first
مانند گذته از دادههای آنالوگ و اینترنت اشیا که قبلاً در دریاچه داده یافت شدهاند، استفاده کنید، زیرا دریاچه داده در حال حاضر بیشتر دادههای ساختاریافته، متنی و سایر دادههای بدون ساختار را در ذخیرهسازی کمهزینه مانند Amazon S3، Azure Blob Storage یا Google Cloud ذخیره میکند.
2- آوردن قابلیت اطمینان و کیفیت به دریاچه داده
- تراکنشها از خواص تراکنشهای ACID پشتیبانی میکند تا از سازگاری دادهها اطمینان حاصل کند زیرا چندین طرف به طور همزمان دادهها را میخوانند یا مینویسند، معمولاً با استفاده از SQL.
- پشتیبانی از طرحوارهها از معماریهای طرحواره DW مانند طرحوارههای Star/Snowflake و مکانیزمهای نظارتی و حسابرسی قوی که ارائه میدهد.
- الزام اجرای طرحواره(Schema enforcement) امکان مشخص کردن طرحواره مورد نظر بروی دادهها و اجرای آن را فراهم میکند و از ایجاد خرابی دادههای بد جلوگیری میکند.
- تکامل طرحواره(Schema evolution) اجازه میدهد تا دادهها به طور مداوم تغییر کنند، و کاربر نهایی را قادر میسازد تا تغییراتی را در یک طرح جدول ایجاد کند که میتواند به طور خودکار اعمال شود، بدون نیاز به DDLهای دست و پا گیر.
3- افزودن کنترلهای حاکمیتی و امنیتی
- پشتیبانی از DML از طریق Scala، Java، Python و SQL API برای ادغام، بهروزرسانی و حذف مجموعههای داده، امکان انطباق با GDPR و CCPA و همچنین سادهسازی موارد استفاده مانند تغییر ضبط دادهها(CDC) را میدهد.
- تاریخچه جزئیات سوابق را در مورد هر تغییری که در دادهها ایجاد شده است ارائه میدهد و یک دنباله حسابرسی کامل از تغییرات(Audit) را ارائه میدهد
- Snapshotهای دادهها، توسعهدهندگان را قادر میسازد تا به نسخههای قبلی دادهها برای ممیزی، بازگرداندن یا بازتولید آزمایشها، دسترسی داشته باشند و به آنها برگردند.
- کنترل دسترسی مبتنی بر نقش(Role)، امنیت و حاکمیت دقیقی را برای سطح سطر/ستون بروی جداول فراهم میکند.
4- بهینه سازی عملکرد
فعال شدن تکنیکهای بهینهسازی مختلف مانند ذخیرهسازی نهان، خوشهبندی چند بعدی، مرتبسازی z و پرش دادهها(data skipping) با استفاده از متادادههای آماری بروی فایلها و فشردهسازی دادهها برای اندازهگیری مناسب فایلها
5- پشتیبانی از یادگیری ماشینی
- پشتیبانی از انواع دادههای مختلف برای ذخیره، پالایش، تجزیه و تحلیل و دسترسی به دادهها برای بسیاری از برنامههای کاربردی جدید، از جمله تصاویر، ویدئو، صدا، دادههای نیمه ساختار یافته و متن
- خواندن مستقیم کارآمد حجم زیادی از دادهها(بصورت غیر SQL) برای اجرای آزمایشهای یادگیری ماشین با استفاده از کتابخانههای R و Python
- پشتیبانی از DataFrame API از طریق یک API اعلامی(declarative) داخلی DataFrame با بهینهسازیهای پرس و جو برای دسترسی به داده در بارهای کاری ML، زیرا سیستمهای ML مانند TensorFlow، PyTorch و XGBoost رویکرد DataFrames را به عنوان انتزاع اصلی برای دستکاری دادهها پذیرفتهاند.
- نسخهسازی دادهها (Data Versioning) برای آزمایشهای ML، ارائه Snapshotهایی از دادهها که تیمهای علم داده و یادگیری ماشین را قادر میسازد به نسخههای قبلی دادهها برای ممیزی و بازگرداندن یا بازتولید آزمایشهای ML دسترسی پیدا کنند و به آنها برگردند.
6- ایجاد فضای باز
- فرمتهای فایل باز مانند Apache Parket و ORC
- Open API یک API باز ارائه میدهد که میتواند به طور موثر به دادهها مستقیماً بدون نیاز به موتورهای اختصاصی و قفل شده به ارائه دهندگان دسترسی داشته باشد.
- پشتیبانی از زبانهای دیگر (نه تنها برای دسترسی SQL) بلکه انواع ابزارها و موتورهای دیگر، از جمله یادگیری ماشین و کتابخانههای Python/R
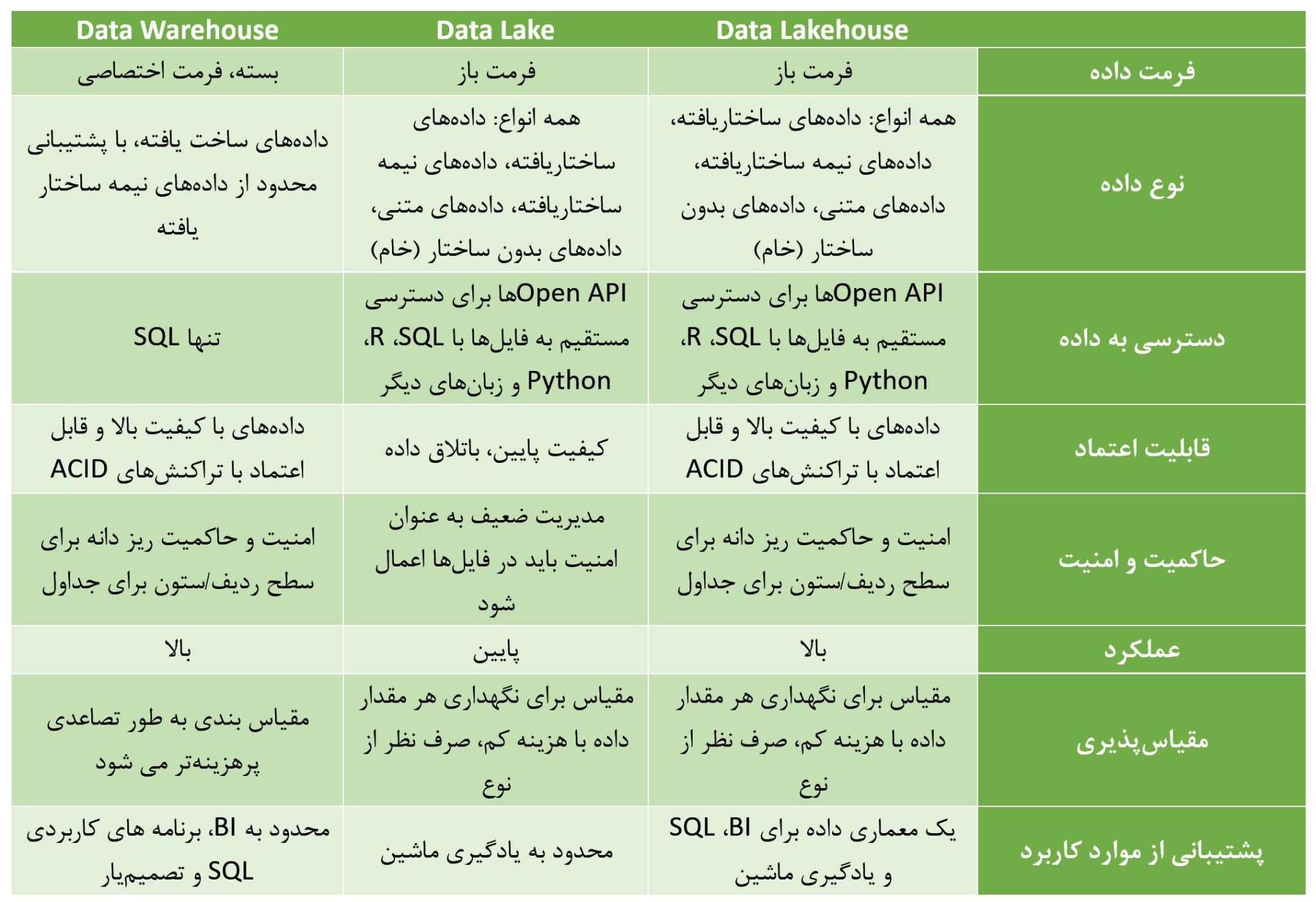
معماری دریاچه دادهها فرصتی قابل مقایسه با آنچه در سالهای اولیه انبار داده مشاهده شد، ارائه میدهد. توانایی منحصر به فرد Lakehouse برای مدیریت دادهها در یک محیط باز، ترکیب انواع دادهها از تمام بخشهای سازمانی، و ترکیب تمرکز علم داده در دریاچه داده با تجزیه و تحلیل کاربر نهایی انبار داده، ارزش باورنکردنی را برای سازمانهای شما بوجود میآورد.