
در این پست، به معرفی آپاچی کافکا به عنوان یک سکوی انتقال پیام توزیعشده، مقیاسپذیر و با کاربرد گسترده خواهیم پرداخت. همچنین به صورت اجمالی اجزای مختلف کافکا و چگونگی ارتباط و انسجام آنها در دستیابی به توزیع قابل اطمینان پیام را توضیح میدهیم.
موارد زیر در این مقاله بررسی خواهد شد:
- آپاچی کافکا: تاریخچه
- معماری کافکا
- تاپیکهای پیام
- پارتیشنهای پیام
- فاکتور تکرار و لاگهای تکرار شده
- تولیدکنندههای پیام
- مصرفکنندگان پیام
- نقش زوکیپر
آپاچی کافکا : تاریخچه
حتماً بسیاری از شما از پورتال لینکدین برای حرفه و کسبوکار خود استفاده کردهاید. سیستم کافکا اولین بار توسط تیم فنی لینکدین ساخته شد. لینکدین، با استفاده از اجزای سفارشی شده داخلی و با کمک ابزارهای متنباز موجود، یک سیستم جمعآوری رخدادهای وضعیت نرمافزار ساخت. این سیستم به منظور جمعآوری دادههای فعالیت کاربران در پورتال لینکدین استفاده میشد. آنها از دادههای فعالیتی، برای نشان دادن اطلاعات مرتبط با کاربران در پورتال وبشان استفاده میکردند. این سیستم، ابتدا به صورت یک سرویس جمعآوری کننده لاگ و مبتنیبر XML ساخته شده بود، و دادهها با استفاده از ابزارهای مختلف ETL پردازش میشد. با اینحال، این مدل مدت زیادی دوام نداشت. آنها با مشکلات متعددی مواجه شدند. برای حل این مشکلات، سیستمی به نام کافکا ساخته شد.
لینکدین، کافکا را به عنوان سیستم انتشار/اشتراک توزیعشده و تحملپذیری در مقابل خطا توسعه داد. کافکا پیامهای مرتب شده را در قالب تاپیکها ثبت میکند. برنامهها میتوانند پیامهایی را در تاپیکها تولید و یا از آن دریافت و مصرف کنند. تمام پیامها به صورت لاگهایی در فایل سیستمهایی پایدار ذخیره میشوند. کافکا یک سیستم WAL (write-ahead logging) است، که تمام پیامهای منتشر شده را پیش از دسترسی مصرفکننده، در داخل فایلهای لاگ مینویسد. مشترکان/مصرفکنندگان میتوانند این پیامهای نوشته شده را در صورت نیاز در چارچوب زمانی مناسبی بخوانند. در واقع، کافکا با در نظر داشتن اهداف زیر ساخته شده است:
- اتصال سست (حداقل وابستگی) بین مصرفکنندهها و تولید کنندگان پیام
- ماندگاری دادههای پیام به منظور پشتیبانی از انواع مختلف مسائل مصرف داده و مدیریت شکست
- حداکثر توانپردازشی بین دو سیستم استفاده کننده از کافکا با کمترین تأخیر در اجزا
- مدیریت انواعدادهها و فرمت دادههای متنوع با استفاده از فرمت دادههای دودویی
- مقیاسپذیری خطی سرورها بدون اثرگذاری بر تنظیمات کلاسترهای موجود
باید توجه داشت که یکی از کاربردهای معمول کافکا، در معماری پردازش جریانی آن است. با منطق مورد اطمینان ارسال پیام، کافکا به پردازش نرخ بالایی از دادههای رویداد کمک میکند. علاوه بر این، قابلیت پخش پیام و همچنین پشتیبانی از انواع مختلف مصرفکننده را نیز ارائه میدهد.
این امکانات در ساختن معماری جریان دادۀ تحملپذیر در برابر خطا، و پشتیبانی از سرویسهای مختلف هشدار و اعلان، مفید خواهند بود.
معماری آپاچی کافکا
در این بخش معماری کافکا به شما معرفی خواهد شد. در انتهای این بخش به درک روشنی از معماری منطقی و فیزیکی کافکا خواهیم رسید. در ادامه خواهیم دید که چگونه اجزای کافکا از نظر منطقی در کنار یکدیگر قرار گرفتهاند.
هر پیام در تاپیکهای کافکا، مجموعهای از بایتهاست. این مجموعهها به صورت آرایه نمایش داده میشوند. تولیدکنندگان، برنامههایی هستند، که اطلاعات را در صفهای کافکا(تاپیک) ذخیره میکنند. تولیدکنندگان پیامها را به تاپیکهای کافکا، که میتوانند هر نوعی پیام را ذخیره کنند، میفرستند. هر تاپیک به پارتیشنهایی تقسیم میشود. در هر پارتیشن پیامها به ترتیب دریافت ذخیره میشود. دو عملیات اصلی که تولیدکنندگان/مصرفکنندگان میتوانند در کافکا انجام دهند عبارتند از: تولیدکنندگان که دادهها را در قالب یک لاگ به انتهای فایلهای WAL اضافه میکنند و مصرفکنندگان که پیامهای داخل این فایلهای لاگ را، که مربوط به یک پارتیشن در یک تاپیک مشخص است، واکشی میکنند. از نظر فیزیکی، هر تاپیک بین کارگزارهای مختلف کافکا پخش میشود، که هرکدام از این کارگزارها یک یا چند پارتیشن از هر تاپیک را میزبان میشود.
در حالت ایدهآل، کلاستر کافکا باید تعداد یکسانی از پارتیشنها به ازای هر کارگزار و تمام تاپیکها در هر ماشین داشته باشد. مصرفکنندگان، برنامه ها یا فرآیندهایی هستند، که اشتراک یک تاپیک را دارند و پیامهای این تاپیک را دریافت میکنند.
شکل زیر، لایۀ مفهومی کلاستر کافکا را نمایش میدهد:
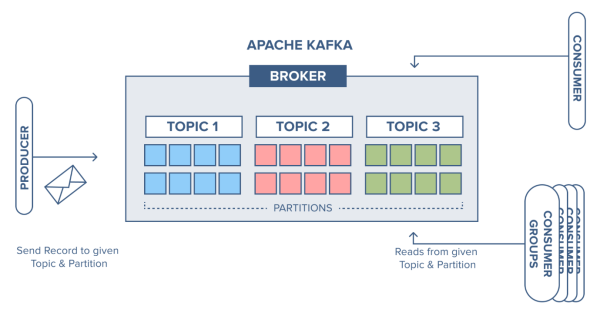
در این شکل معماری منطقی کافکا و چگونگی هماهنگی اجزای منطقی مشخص شده است. همانطورکه درک بخشهای منطقی معماری کافکا حائز اهمیت است، درک معماری فیزیکی کافکا نیز مهم است. یک کلاستر کافکا اساساً از یک یا چند سرور (گره) تشکیل شده است. شکل زیر، تصویری از کلاستر چند گره کافکا را نمایش میدهد:
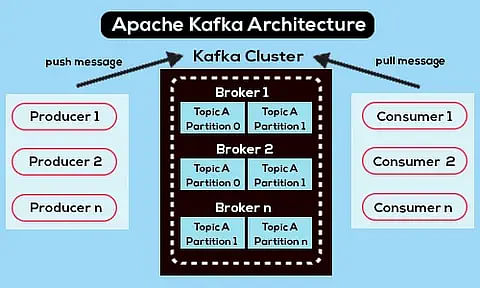
کلاستر کافکا معمولاً از چندین کارگزار تشکیل شده است. این مسئله، به توازن بار خواندن و نوشتن پیام در کلاستر کمک میکند. هریک از کارگزارها، بدون حالت(stateless) هستند. اما، برای نگهداری از حالتهایشان از زوکیپر استفاده میشود. هر یک از پارتیشنهای تاپیکها دارای یک کارگزار به عنوان گره مدیر(master)، و صفر یا چند کارگزار به عنوان گرههای دنبالکننده(slave) هستند. گره مدیر، تمامی درخواستهای نوشتن و خواندن پارتیشنهای مربوطهاش را مدیریت میکند. گرههای دنبالکننده، در پسزمینه، دادههای گره مدیر را دریافت و در خود تکرار میکنند، بدون آنکه به صورت فعال با کارکرد گره مدیر تداخل داشته باشند. میتوان گرههای دنبالکنند را به عنوان پشتیبانی برای گره مدیر در نظر گرفت، و در صورت شکست این گره، یکی از دنبالکنندگان به عنوان گره مدیر انتخاب خواهد شد.
این نکته را باید در نظر داشت که هر سرور در کلاستر کافکا، یا گره مدیر برخی از پارتیشنهای یک تاپیک است، یا گره دنبالکنندهای برای دیگران. در این صورت، بار بر روی هر سرور به صورت برابر متوازن خواهد بود. انتخاب گره مدیر کارگزارها در کافکا با کمک زوکیپر انجام میشود.
زوکیپر، جزئی مهم از کلاستر کافکا است، که حالت کارگزارها و مصرفکنندگان کافکا را مدیریت و هماهنگ میکند. زوکیپر دائما، افزودهشدن یا شکست و از کلاستر خارج شدن کارگزارهای موجود در کلاستر کافکا را پیگیری میکند. در نتیجه، تولیدکنندهها یا مصرفکنندگان تاپیکهای کافکا را از حالت کلاستر مطلع میکند. این مسئله، به تولیدکنندهها و مصرفکنندگان اجازه میدهد که هماهنگ با کارگزارها فعال عمل کنند. زوکیپر همچنین اینکه کدام کارگزار مدیر کدام پارتیشن یک تاپیک است را نیز ثبت کرده و این اطلاعات را، هنگام نوشتن و خواندن پیامها، به تولیدکنندهها یا مصرفکنندهها ارائه میدهد.
تاکنون با کاربردهای تولیدکننده و مصرفکننده در کلاستر کافکا آشنا شدهاید. تولیدکنندهها، دادهها را به کارگزارها منتقل میکنند. در زمان انتشار داده، تولیدکنندهها به دنبال گره مدیر انتخاب شده (کارگزار) مربوط به یک پارتیشن تاپیک میگردند، و به صورت خودکار پیام را برای سرور کارگزار آن گره میفرستند. به صورت مشابه، مصرفکننده، پیامها را، از طریق همین کارگزارها، میخواند.
از آنجاییکه کارگزارها در کافکا بدون حالت هستند، مصرفکننده حالت خود را در یک تاپیک کافکا (بنام __consumed_offset) ثبت میکند. این طراحی به مقیاسپذیری کافکا بسیار کمک میکند. مقدار آفست مصرفکننده توسط این تاپیک نگهداری میشود. در نسخههای پیشین کافکا، از زوکیپر برای ذخیرهسازی آفست استفاده مصرف کنندهها استفاده میشود. البته میتوان هر دو محل را برای ذخیرهسازی آفست استفاده کرد. مصرفکننده تعداد پیامهای مصرفشده را با استفاده از آفست پارتیشن ثبت میکند. نهایتاً، آفست پیام را در تاپیک اشاره شده در بالا ثبت میکند یا به زوکیپر اعلام میکند، به این معنی که مصرفکننده تمام پیامهای پیشین را مصرف کرده است.
امیدواریم که تا به اینجا، با معماری کافکا آشنا شده و تمام اجزای فیزیکی و منطقی آن را درک کرده باشید. در بخش بعد، هر یک از این اجزاء را به صورت تفضیلی بررسی خواهیم کرد.
تاپیکهای پیام
اگر با توسعه نرمافزار آشنا باشید، یقیناً واژههایی مانند پایگاهداده، جداول، رکورد و غیره را شنیدهاید. در یک پایگاهداده، چندین جدول قرار دارد؛ برای مثال، اقلام، قیمتها، فروش، موجودی، خرید و بسیاری دیگر. هر جدول شامل دادههای از یک دستهبندی مشخص میباشد. با وجود این، یک برنامه شامل دو بخش میباشد: یکی قرار دادن رکوردها داخل این جداول و دیگری خواندن رکوردها از جداول. در اینجا، جداول همان تاپیکها در کافکا هستند، برنامههایی که دادهها را در جداول گذاشته تولیدکنندهها، و برنامههایی که دادهها را میخوانند، مصرفکنندها هستند.
در یک سیستم انتقال پیام، پیامها باید در جایی ذخیره شوند. در کافکا، پیامها را داخل تاپیکها ذخیره میکنیم. هر تاپیک به یک دستهبندی مشخص تعلق دارد، به این معنی که ممکن است یک تاپیک داشته باشید که آن اطلاعات اقلام و دیگری اطلاعات فروشها را ذخیره میکند. تولیدکنندهای که بخواهد پیامی را ارسال کند، آن را به دستۀ تاپیکهای مخصوص خود میفرستد. مصرفکنندهای که بخواهد این پیامها را بخواند باید مشترک دستۀ تاپیکهایی شود که به آن مربوط بوده و آن را مصرف کند. در اینجا اصطلاحاتی وجود دارد که باید با آنها آشنا باشیم:
- زمان نگهداری(Retention Period): پیامهای داخل تاپیکها لازم است که برای زمان مشخصی ذخیره شوند، تا فارغ از توانپردازشی، در فضا صرفهجویی شود. زمان نگهداری که به صورت پیشفرض 168 ساعت(هفت روز) است، قابل پیکربندی به مدت زمان دلخواه است. کافکا پیامها را تا پایان دورۀ تعریف شده نگه میدارد، و در نهایت مستقل از آنکه آنها مصرق شده باشند یا خیر، آنها را پاک میکند.
- سیاست نگهداری فضا(Space Retention Policy): میتوانیم تاپیکها کافکا را به صورتی پیکربندی کنیم که اگر اندازه پیامها از آستانۀ مشخصی از حجم ذخیرهسازی تجاوز کند، آنها را پاک کند. این مسئله میتواند زمانی اتفاق بیفتد که پیش از پیادهسازی کافکا در سازمان خود، برنامهریزی ظرفیت کافی را نکرده باشید.
- آفست: در کافکا، به هر پیام عددی اختصاص داده میشود که آفست نامیده میشود. تاپیکها شامل تعدادی پارتیشن هستند. هر پارتیشن پیامها را به ترتیب رسیدن، ذخیره میکند. مصرفکنندها، دریافت پیامها را از طریق آفستشان تصدیق میکنند، به این معنی که تمام پیامهای پیش از یک آفست پیام مشخص را دریافت کردهاند.
- پارتیشن: هر تاپیک در کافکا شامل تعداد ثابتی از پارتیشنهاست. هنگام ایجاد یک تاپیک در کافکا، باید تعداد پارتیشنها را مشخص کنید، به منظور دستیابی به حداکثر توانپردازشی، پارتیشنها در بین ماشینهای کارگزار توزیع میشوند.
- تراکم(Compaction): تراکم تاپیکها در کافکای نسخۀ 0.8 معرفی شد. هیچ راهی برای تغییر پیامهای پیشین در کافکا وجود نداشت؛ پیامهایی که زمان نگهداری آنها به پایان میرسید، پاک میشدند. اما گاهی ممکن است پیامهای جدیدی را با کلید یکسان و با تغییراتی در مقدار آن، دریافت کنید؛ و در سمت مصرفکننده ممکن است بخواهید آخرین دادهها را پردازش کنید. قابلیت تراکم، این امکان را با متراکم کردن تمام پیامهایی که کلید یکسان دارند و ایجاد یک نگاشت از آفست برای (کلید: آفست آخرین دادهی آن کلید) فراهم میکند. این ویژگی به حذف پیامهای تکراری(پیامهایی با کلیدهای یکسان) در میان تعداد زیادی پیام کمک میکند.
- گره مدیر: پارتیشنها در سرتاسر کلاستر کافکا بر حسب یک فاکتور تکرار(Replication Factor) مشخص، تکرار میشوند. هر پارتیشن یک کارگزار مدیر و تعدادی دنبالکننده دارد، که تمام درخواستهای نوشتن و خواندن ارسال شده به پارتیشن تنها از طریق مدیر صورت میگیرد. اگر مدیر دچار شکست شود، یک مدیر دیگر انتخاب شده و پروسه ادامه مییابد.
- بافر کردن: کافکا در هر دو سمت تولیدکننده و مصرفکننده، به منظور افزایش توانپردازشی و کاهش ورودی/خروجی (I/O)، پیامها را بافر میکند.
پارتیشنهای پیام
فرض کنید که یک جدول از خریدها در اختیار داریم و بخواهیم رکوردهای یکی از اقلام را از جدول خریدها که متعلق به یک دستۀ مشخص، مثلاً وسایل الکترونیکی است، را بخوانیم. به صورت معمول، ابتدا رکوردهای دیگر را با فیلتر کردن حذف میکنیم، اما اگر میتوانستیم جدولمان را به صورتی پارتشینبندی کنیم که رکوردهای مورد نظر را با سرعت بیشتر بخوانیم بهتر نبود؟
این دقیقاً همان حالتی است که تاپیکها را در کافکا به پارتیشنهایی، که با عنوان واحدهای موازیسازی شناخته میشوند، تقسیم میکنیم. به این صورت، تا یک محدودهای هرچه تعداد پارتیشنها بیشتر باشد، توانپردازشی بالاتر است. البته این موضوع به این معنی نیست که هر چه بیشتر پارتیشن انتخاب کنیم. در ادامه دربارۀ مزایا و معایب افزایش تعداد پارتیشنها بحث خواهیم کرد.
هنگام ایجاد تاپیکها، میتوانید تعداد پارتیشنهایی که برای آنها نیاز دارید را مشخص کنید. هر پیام، مبتنی بر مکانیسم ارسال کلید یک پیام به یک تقسیمکننده(Partitioner) ومشخص شدن پارتیشن آن، به یکی از پارتیشنها افزوده میشود و یک عدد بنام آفست به هر پیام نسبت داده میشود. با استفاده از تقسیمکننده پیشفرض، کافکا اطمینان حاصل میکند که پیامهایی که کلید مشابه دارند همگی به پارتیشن یکسانی میروند؛ با محاسبه تابع هَش مخصوص کلید پیام، آن پیام را به پارتیشن اضافه میکند. مرتبسازی پیامها براساس زمان در تاپیکها امکانپذیر نیست، اما در یک پارتیشن، این مسئله را میتوان تضمین کرد؛ به این صورت که پیامهایی که دیرتر میرسند به انتهای پارتیشن افزوده میشوند.
پارتیشنها تحملپذیر نسبت به خطا هستند؛ آنها به تعداد فاکتور تکرار در سرتاسر کارگزارها کافکا، تکرار میشوند. هر پارتیشن مدیر خود را دارد، که پیامها را به مصرفکنندهای که بخواهند آن را از پارتیشن بخواند، ارائه میکند. اگر مدیر دچار خرابی شود، مدیر دیگری توسط زوکیپر انتخاب میشود که پیامها را به مصرفکنندهها ارائه میکند. به این طریق، حداکثر توان پردازشی و حداقل تأخیر حاصل میشود.
حال به مزایا و معایت داشتن تعداد زیادی پارتیشن میپردازیم:
- توان پردازش بالا: پارتیشنها راهی برای دستیابی به موازیسازی در کافکا هستند. عملیات نوشتن بر پارتیشنهای مختلف به صورت موازی اتفاق میافتد. تمام عملیات زمانبر نیز به صورت موازی رخ میدهند؛ این عملیات حداکثر منابع سختافزاری را به کار میگیرند. از طرفی، یک پارتیشن به یک مصرفکننده در یک گروه مصرفکنندگان تخصیص داده میشود؛ در نتیجه مصرفکنندگان مختلف در گروههای مختلف میتوانند از یک پارتیشن یکسان بخوانند، اما مصرفکنندگان مختلف از یک گروه مصرفکنندگان یکسان اجازۀ خواندن از پارتیشن یکسان را ندارند. پس، درجۀ موازیسازی در یک گروه مصرفکنندگان واحد وابسته به تعداد پارتیشنهایی است که از آن میخواند. تعداد زیاد پارتیشنها میتواند منجر به توانپردازشی بالا شود.
انتخاب تعداد پارتیشنها وابسته به مقدار توانپردازشی مد نظر شماست. اما در سوی مقابل توانپردازشی برای تولیدکننده وابسته به معیارهایی مانند سایز دسته، نوع فشردهسازی، تعداد تکرارها، انواع تصدیقها(acknowledgement)، و پیکربندیهای دیگر است.
با این حال، باید در تغییر تعداد پارتیشنها محتاط باشیم. نگاشت پیامها به پارتیشنها کاملاً وابسته به کد هش تولید شده براساس کلید پیام است که باعث میشود پیامها با کلید یکسان بر روی پارتیشنی یکسان نوشته شوند. این مسئله تضمین میکند که مصرفکننده پیامها را به ترتیبی که در پارتیشن ذخیره شدهاند، دریافت کند. اگر تعداد پارتیشنها را تغییر دهیم، توزیع پیامها تغییر میکند و برای ترتیب پیامها که مصرفکنندهای منتظر ترتیب مشترک شده قبلی بوده است، دیگر تضمینی وجود ندارد.
- افزایش حافظۀ تولیدکننده: افزایش تعداد پارتیشنها ما را مجبور میکند که حافظۀ تولید کننده را افزایش بدهیم. یک تولیدکننده پیش از روانه کردن داده به سمت کارگزار و درخواست برای ذخیرهسازی آن در پارتیشن، کارهایی را به صورت داخلی انجام میدهد. تولیدکننده، پیامهای ورودی به ازای هر پارتیشن را بافر میکند. هنگامیکه زمان مشخص شدهای فرا برسد، تولیدکننده پیامها را به کارگزار میفرستد و آنها را از بافر حذف میکند.
اگر تعداد پارتیشنها را افزایش دهیم، حافظۀ اختصاص داده شده برای بافر کردن ممکن است در فاصله زمانی بسیار کوتاهی متجاوز از حد موردنظر شود، و تولیدکننده باید تولید پیامها را تا ارسال دادههای بافر شده به کارگزار، مسدود کند. در نتیجه، توانپردازشی میتواند کاهش یابد. برای غلبه به این مسئله، باید در پیکربندی حافظۀ بیشتری برای تولیدکننده در نظر گرفته شود، که به اختصاص دادن حافظۀ اضافی به تولیدکننده منجر شود.
- مسئله دسترسپذیری بالا: کافکا با قابلیتهای دسترسیپذیری بالا، توانپردازشی بالا، و توزیع شده بودن سیستم انتقال پیام شناخته میشود. کارگزارها کافکا هزاران پارتیشن از تاپیکهای مختلف را ذخیرهسازی میکنند. خواندن و نوشتن از پارتیشنها بواسطه مدیر هر پارتیشن صورت میگیرد. عموماً، اگر مدیر دچار شکست شود، انتخاب یک مدیر جدید تنها چند میلیثانیه طول میکشد. نظارت بر شکستها از طریق کنترلکنندهها انجام میشود. کنترلکنندهها یکی از کارگزارها هستند. مدیر انتخاب شده به درخواستهای تولیدکنندهها و مصرفکنندگان رسیدگی میکند. پیش از رسیدگی به درخواست، کارگزار، فرادادۀ پارتیشن را از زوکیپر میخواند. با وجود این، برای شکستهای معمول و مورد انتظار، پنجره زمانی بسیار کمی در حدود چند میلیثانیه طول میکشد، اما در شکستهای غیرقابل پیشبینی، مانند از کار انداختن یک کارگزار به صورت غیر عمد، ممکن است بر اساس تعداد پارتیشنها تا چند ثانیه تأخیر به وجود آید. فرمول کلی را میتوان متصور شد:
زمان تأخیر = (تعداد پارتیشن/تکرار * زمان خواندن فراداده یک پارتیشن واحد)
احتمالی دیگر این است که کارگزاری که دچار شکست شده، کنترلکننده باشد، و زمان جایگزینی کنترلکننده بسته به تعداد پارتیشنها، خواندن فرادادۀ هر پارتیشن توسط کنترلکنندۀ جدید، و زمان آغاز کنترلکننده با افزایش تعداد پارتیشنها افزایش مییابد.
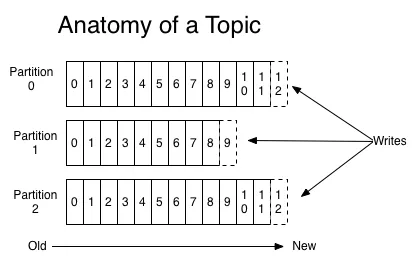
فاکتور تکرار و لاگهای تکرار شده
فاکتور تکرار یکی از معیارهای مهم در دستیابی به قابلیت اطمینان در کلاسترهای کافکا است. تکرارهایی از لاگهای پیامهای هر پارتیشن مربوط به هر تاپیک در سرورهای مختلفی در کلاستر کافکا نگهداری میشوند و میتوان آن را برای هر تاپیک، جداگانه تنظیم کرد. به این صورت که ممکن است ضریب تکرار برای یک تاپیک 3، و برای تاپیک دیگر ضریب تکرار 5 باشد. یکی از تکرارها به عنوان گره مدیر انتخاب میشود تمام خواندنها و نوشتنها از طریق این گره صورت میگیرد؛ اگر این گره دچار شکست شود، یکی از دنبالکنندگان(تکرار) به عنوان مدیر انتخاب میشود.
دنبالکنندگان عموماً، یک نسخه از لاگ گره مدیر را نگهداری میکنند؛ یعنی مدیر تا زمانی که از تمام دنبالکنندگان تصدیق نگیرد، پیام را تثبیت شده اعلام نخواهد کرد. راههای مختلفی در پیادهسازی الگوریتم تکرار لاگ وجود دارد. این روشها باید اطمینان حاصل کنند که اگر مدیر به تولیدکننده اعلام کند پیام ثبت شده است، برای خواندن در دسترس مصرف کننده قرار میگیرد.
برای دستیابی به چنین سازگاری در تکرارها، دو رویکرد وجود دارد. در هر دو رویکرد، درخواستهای خواندن و نوشتن از طریق مدیر پردازش میشود. بین این دو رویکرد تفاوت اندکی در شیوۀ مدیریت تکرارها و انتخاب مدیر وجود دارد:
- رویکرد مبتنی بر حد نصاب: در این رویکرد، گره مدیر تنها زمانی پیامها را تثبیت شده علامتگذاری میکند که اکثر تکرارها دریافت پیام را تصدیق کرده باشند. اگر مدیر دچار شکست شود، انتخاب مدیر جدید با همانگی بین دنبالکنندگان اتفاق میافتد. الگوریتمهای زیادی برای انتخاب مدیر وجود دارد و بررسی این الگوریتمها خارج از مباحث این پست است. زوکیپر در انتخاب مدیر، رویکردی مبتنی بر حد نصاب دارد(در مقاله مربوط به زوکیپر به این موضوع اشاره میکنیم).
- رویکرد پشتیبان اولیه: کافکا از رویکردهای مختلفی برای نگهداری از تکرارها استفاده میکند؛ گره مدیر، پیش از تثبیت پیام، منتظر تصدیقی از تمام دنبالکنندگان میشود. اگر مدیر دچار شکست شود، هر یک از دنبالکنندگان میتواند جایگزین او شود.
این رویکرد میتواند هزینه بیشتری در تأخیر و توانپردازشی داشته باشد، اما سازگاری بهتری را در پیامها یا دادهها تضمین میکند. در هر پارتیشن مجموعهای از تکرارهای هماهنگ، یا ISR(In Sync Replica)، وجود دارد (IRS به مجموعه کارگزارهای دنبالکننده یک پارتیشن گفته میشود که آفست پیامهای آنها با گره مدیر خود Sync باشد). در نتیجه، برای هر پارتیشن یک مدیر و یک ISR خواهیم داشت که اطلاعات آنها در زوکیپر ذخیره میشود. حال روال خواندن و نوشتن به صورت زیر اتفاق میافتد:
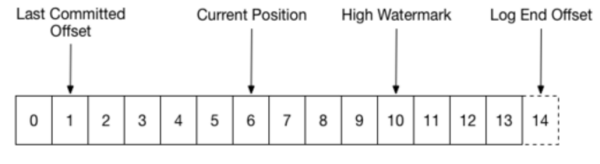
- نوشتن: تمام مدیرها و دنبالکنندگان لاگ محلی خود را دارند که انتهای آفست لاگ را که بخش پایانی لاگ است پیش خود نگه میدارند. آفستِ آخرین پیام تثبت شده High Watermark نامیده میشود(مصرفکنندهها فقط میتوانند تا آفست High Watermark دادههای یک پارتیشن را دریافت کنند). هنگامی که یک کاربر درخواست میکند تا پیامی را در پارتیشن بنویسد، ابتدا مدیر پارتیشن را از زوکیپر انتخاب کرده و یک درخواست نوشتن ایجاد میکند. مدیر، پیام را بر روی فایل لاگ و در انتهای آن مینویسد و سپس منتظر دنبالکنندگان داخل ISR میشود تا تصدیق خود را بفرستند. زمانی که تصدیق دریافت شد، اشارهگر High Watermark حرکت میکند و یک تصدیق به کاربر میفرستد. اگر هر یک از دنبالکنندگان حاضر در ISR دچار شکست شوند، مدیر آنها را از ISR حذف کرده و عملیات را با دیگر دنبالکنندگان ادامه میدهد. زمانی که دنبالکنندۀ دچار شکست شده، بازگردد، با هماهنگ ساختن لاگها، عقبماندگی خود را با گره مدیر جبران میکند. سپس، مدیر دوباره آن را به ISR اضافه میکند.
- خواندن: تمام خواندنها تنها از طریق مدیر صورت میگیرد. پیامی که توسط مدیر با موفقیت تصدیق شود برای خواندن در دسترس کاربر قرار خواهد گرفت.
در نمودار زیر، شیوۀ پیادهسازی لاگ کافکا روشن شده است:
تولیدکنندههای پیام
در کافکا، تولیدکننده مسئول ارسال داده به پارتیشن مربوط به تاپیکی است که برای آن داده تولید میکند. تولیدکنندگان عموماً خود داده را بر روی پارتیشنها نمینویسند، بلکه درخواست نوشتن پیامها را ایجاد و آنها را به کارگزار مدیر ارسال میکنند. پارتیشنکننده مقدار هش کلید پیام را محاسبه میکند، که این امر به تولیدکننده کمک میکند پارتیشن مناسب را انتخاب کند.
مقدار هش عموماً بروی کلید پیامی که هنگان نوشتن پیام در تاپیک کافکا ارائه میدهیم، محاسبه میشود. یک پیام با کلید Null به روش نوبت گردشی در سرتاسر پارتیشنها توزیع میشود تا از توزیع یکنواخت پیامها اطمینان حاصل شود. درخواست نوشتن پیام در پارتیشن یک تاپیک از طریق کارگزار مدیر انجام میشود. تولیدکننده با توجه به تنظیمات انجام شده، منتظر تصدیق پیام میماند. معمولاً این انتظار تا زمانی طول میکشد که تکرارهای یک پیام بهخصوص با موفقیت تصدیق شود.
باید توجه داشت که تا زمانی که تمام تکرارها ثبت پیام را تصدیق نکرده باشند، پیام برای خواندن در دسترس نخواهد بود. این نوع تنظیم به صورت پیشفرض بوده و تضمین میکند که در صورت شکست کارگزار مدیر، پیام از دست نخواهد رفت.
با این حال، میتوانید پیکربندی تصدیق پیام را بر روی 1 تنظیم کنید، در این صورت، فرض بر آن است که اگر پیامی توسط مدیر ثبت شود، برای خواندن در دسترس خواهد بود و تولیدکنندۀ کافکا میتواند پیام بعدی را تولید کنید. این تنظیمات میتواند هزینه زیادی داشته باشد، زیرا اگر پیش از ثبت پیام توسط تکرارها، کارگزارهای مدیر دچار شکست شوند، پیام از دست خواهد رفت. این پیکربندی منجر به ماندگاری کمتر اما توانپردازشی بیشتر خواهد شد. با وجود این، اگر از دست رفتن حتی یک پیام به عنوان بخشی از برنامه برای مصرفکننده مهم باشد، بهتر است که ملاحظاتی در توانپردازشی کرد و از این روش استفاده نکرد.
مصرفکنندگان پیام
مصرفکننده، هر بخشی است که در تاپیکهای کافکا اشترک دارد. هر مصرفکننده، عضوی از یک گروه مصرفکنندگان است و برخی از گروههای مصرفکنندگان شامل چندین مصرفکننده هستند.
دو مصرفکننده از گروهی مشابه نمیتوانند پیامی از یک پارتیشن مشابه را مصرفکنند زیرا در این صورت منجر به مصرف پیامها بدون ترتیب خواهد شد. اما، مصرفکنندگان از گروهی یکسان میتوانند پیامهایی از پارتیشنهای مختلف از تاپیکی یکسان را همزمان مصرفکنند. به صورت مشابه، مصرفکنندگان از گروههای مختلف میتوانند به صورت موازی پیامهایی از پارتیشنهای یکسان را بدون تأثیر بر ترتیب مصرف، مصرف کنند.
روشن است که گروهها نقش مهمی ایفا میکنند؛ در نسخههای ابتدایی کافکا، زوکیپر برای مدیریت گروهها استفاده میشد، اما در نسخۀ جدیدتر، کافکا از پروتکل گروه داخلی مخصوص بهخود استفاده میکند. یکی از کارگزارها به عنوان هماهنگکنندۀ گروه ایفای نقش میکند و مسئول تخصیص و مدیریت پارتیشنها برای گروهها است.
قبلا دربارۀ تخصیص آفست به یک پیام در یک پارتیشن صحبت کردیم؛ هر مصرفکننده، آفست را خوانده و آفست را در هماهنگکنندۀ گروه یا زوکیپر ثبت میکند. چنانچه به هر دلیلی مصرفکننده دچار شکست شود، آفست پیامهای خوانده شده توسط مصرفکننده جدید دریافت شده و دوبار کار را از همانجا شروع خواهد کرد.
آفستها به تضمین پردازش پیامها توسط مصرفکنندگان کمک میکنند، این مسئله برای بسیاری از کاربردهایی حائز اهمیت است که هزینۀ از دست رفتن هر پیامی که بخشی از پردازش است، زیاد است.
نقش زوکیپر
در بخشهای قبل، دربارۀ زوکیپر صحبت کردیم. در معماری کافکا، زوکیپر نقش مهمی ایفا میکند و درک چگونگی عملکرد آن در ثبت حالت کلاستر کافکا بسیار اهمیت دارد. در نتیجه، یک بخش جدا را به نقش کافکا در کلاستر کافکا اختصاص دادیم. در واقع، کافکا بدون زوکیپر نمیتواند کار کند. کافکا از زوکیپر برای عملیاتهای زیر استفاده میکند:
- انتخاب کنترلکننده: کنترلکننده یکی از کارگزارها است که مسئولیت مدیریت پارتیشن با توجه به انتخاب مدیر، ایجاد تاپیک، ایجاد پارتیشن و مدیریت تکرارها را بر عهده دارد. زمانی که یک گره یا سرور خاموش شود، کنترلکنندههای کافکا مدیر پارتیشن را از میان دنبالکنندگان انتخاب میکنند. کافکا از اطلاعات فرادادههای زوکیپر برای انتخاب کنترلکننده استفاده میکند. زوکیپر اطمینان حاصل میکند که در صورت خرابی کنترلکنندۀ فعلی، یک کنترلکنندۀ جدید انتخاب شود.
- فرادادۀ کارگزارها: زوکیپر حالت هر یک از کارگزارهایی که بخشی از کلاستر کافکا هستند را ثبت میکند. او تمام فرادادۀ مربوط به هر کارگزار داخل کلاستر را ثبت میکند. تولیدکننده/مصرفکننده با زوکیپر تعامل دارد تا حالت کارگزار را دریافت کنند.
- فرادادۀ تاپیک: زوکیپر همچنین فرادادههای تاپیک مانند تعداد پارتیشنها، پارامترهای پیکربندی و غیره را ثبت میکند.
- اطلاعات سهمیه کاربر: در نسخههای جدیدتر کافکا، ویژگی سهمیه معرفی شده است. در کافکا، سهمیهها به کاربران برای خواندن و نوشتن پیامهای یک تاپیک، آستانۀ نرخ بایت مورد استفاده برای خواندن و نوشتن پیام را تحمیل میکنند. تمام اطلاعات و حالتهای این ویژگی توسط زوکیپر نگهداری و مدیریت میشود.
- لیستهای کنترل دسترسی (ACL) تاپیکهای کافکا: کافکا دارای ماژول سطح دسترسی داخلی است که به صورت لیستهای کنترل دسترسی (ACL) تعریف میشود. این ACLها، نقش کاربران را تعیین کرده و اینکه هر یک از این نقشها چه نوع دسترسیهایی برای خواندن و نوشتن در تاپیکهای مربوطه دارند. کافکا برای ذخیره تمام ACL ها از زوکیپر استفاده میکند.
نکات ذکر شده، به صورت خلاصه نشان میدهد که نقش زوکیپر در کلاستر کافکا چیست و چرا کافکا بدون زوکیپر نمیتواند عمل کند.
نتیجهگیری
این پست را با بررسی تاریخچه کافکا در ابتدا آغاز کردیم. مشکلات سیستمهای لینکدین را بیان کردیم که به خلق کافکا منجر شد. در ادامه معماری منطقی و سیستمی کافکا را ذکر کردیم. بررسی معماری کافکا از دو منظر به شما کمک میکند تا درک عملکردی و فنی از کافکا کسب کنید. دیدگاه منطقی بیشتر از منظر برقراری جریان داده و آشنایی با چگونی وابستگی اجزاء مختلف به یکدیگر مسئله را بررسی میکند. دیدگاه فنی به شما در طراحی فنی نرمافزارهای تولیدکننده/مصرفکننده و درک طراحی فیزیکی کافکا کمک میکند. دیدگاه فیزیکی، دیدی سیستمیتر از ساختار منطقی است. معماری فیزیکی، نرمافزارهای تولیدکننده، نرمافزارهای مصرفکننده، کارگزارهای (گرهها) کافکا و زوکیپر را پوشش میدهد. در این پست همچنین، بطور خلاصه، به اجزایی که در معماری کافکا موثر هستند، پرداختیم. مبحث کلیدی دیگر، درک چگونگی توازی واحد و سیستم پاتیشنبندی کافکا است. این مسئله، یکی از جنبههای طراحی سیستمهایی با تأخیر کم در کافکا میباشد.