
در این پست قصد داریم در مورد سیستم فایل توزیع شده هدوپ صحبت کنیم. مطابق آنچه در “آپاچی هدوپ” عنوان شد، سکوی هدوپ دارای یک سیستم فایل توزیع شده است که به منظور ایجاد قابلیت دسترسپذیری بالا و بهبود کاراریی، دادهها را در سطح ماشینهای خوشه بصورت بلوکهای دادهای تقسیم میکند. در اینجا قصد داریم این سیستم فایل را با جزیئات بیشتری بررسی کنیم. اما قبل از هرچیز شاید بد نباشد تا چند نمونه از موارد استفاده آن را بررسی میکنیم:
- در سال 2010، فیسبوک ادعا کرد که یکی از بزرگترین مجموعههای HDFS را در اختیار دارد که 21 پتابایت داده را بروی آن ذخیره میکند.
- در سال 2012، فیسبوک اعلام کرد که بزرگترین مجموعهی یک کلاستر HDFS را با قابلیت ذخیره سازی بیش از 100 پتابایت داده را ایجاد کرده است.
- و یاهو نیز بیشتر از 100 هزار CPU در بیشتر از 40 هزار سرور اجراکنندهی هدوپ، با بزرگترین کلاستر هدوپ که دارای 4500 گره پردازشی است را دارا میباشد. به طور کلی، یاهو 455 پتابایت داده در HDFS ذخیره میکند.
- در سال 2013 نیز، اکثر شرکتهای بزرگ موجود در لیست 500 شرکتی که توسط مجلهی Fortune اعلام شدند، شروع به استفاده کردن از هدوپ کردند.
شاید شما هم با من هم عقیده باشید که درک این آمار کمی دشوار باشد. همانطور که در بخشهای قبلی مطرح شد، هدوپ دو واحد اصلی دارد: حافظه و پردازش. وقتی در مورد بخش حافظهی هدوپ صحبت میکنیم، منظور HDFS است که مخفف عبارت سیستم فایل توزیعشدهی هدوپ است. از همین رو در این پست، HDFS را به شما معرفی خواهم کرد و دربارهی موضوعات زیر توضیح خواهم داد:
- HDFS چیست؟
- مزایای HDFS
- ویژگیهای HDFS
اما قبل از توضیح دربارهی HDFS اجازه دهید تا کمی در مورد سیستم فایل توزیع شده توضیح بدهم.
سیستم فایل توزیعشده(DFS)
سیستم فایل توزیعشده به مدیریت دادهها، یعنی فایلها یا پوشههای موجود در چندین کامپیوتر یا سرور میپردازد. به بیان دیگر، DFS سیستم فایلی است که به ما اجازه میدهد دادهها را در بیشتر از چندین گره یا ماشین در یک مجموعه ذخیره کنیم و به چندین کاربر اجازه میدهد که به دادهها دسترسی داشته باشند. بنابراین به طور کلی، یک سیستم فایل توزیع شده اهدافی یکسان با سیستم فایلی که تابحال در اختیار داشتید (برای مثال NTFS در ویندوز، HFS در مک و یا EX4 در لینوکس) را در پیش میگیرد. تنها تفاوت این است که، در حالت سیستم فایل توزیعشده شما داده را به جای یک دستگاه در چند دستگاه ذخیره میکنید. بااینکه فایلها در شبکه ذخیره میشوند، DFS دادهها را به گونهای سازمان داده و نمایش میدهد که کاربری که مشغول کار با دستگاه است حس میکند که تمام دادهها بصورت واحد و در یک دستگاه ذخیره شدهاند.
سیستم فایل توزیع شده هدوپ (HDFS)
سیستم فایل توزیعشدهی هدوپ یا HDFS یک سیستم فایل توزیعشده بر اساس جاوا است که شما را قادر میسازد که دادههای حجیم را در چندین گره در یک کلاستر هدوپ ذخیره کنید. بنابراین، اگر هدوپ را نصب کنید، به HDFS به عنوان سیستم ذخیرهسازی دادهها در فضای توزیعشده دسترسی پیدا میکنید.
در ابتدا اجازه بدهید مثالی بزنیم تا این مسئله را متوجه شوید. تصور کنید که 10 دستگاه یا 10 کامپیوتر دارید که هر کدام هارد درایوی با ظرفیت 1 ترابایت دارند. در این حالت، HDFS میگوید که اگر شما هدوپ را به عنوان سکویی بروی این ده ماشین نصب کنید، به HDFS به عنوان سرویس ذخیره دسترسی خواهید داشت. سیستم فایل توزیعشدهی هدوپ بصورتی توزیع شدگی را ایجاد میکند که از حافظهی اختصاصی هریک از دستگاهها برای ذخیرهسازی دادهها استفاده میکند.

وقتی شما از طریق هر کدام از 10 گره موجود در مجموعهی هدوپ به سیستم فایل توزیعشدهی هدوپ دسترسی پیدا میکنید، احساس میکنید که وارد یک ماشین بزرگ با ظرفیت حافظهی 10 ترابایتی (حافظهی کل 10 گره) شدهاید. به این معنا است که شما میتوانید یک فایل 10 ترابایتی را طوری ذخیره کنید که در تمام 10 گره (هرکدام 1 ترابایت) توزیع شود. بنابراین، این روند به محدودیتهای فیزیکی هر یک از گرهها محدود نمیشود.
مزایای هدوپ
محاسبات توزیعشده و موازی:
همانطورکه میدانید مسائل مطرح در حوزه کلان داده معمولا با حجم بالایی از دادهها سر و کار دارند. این مسائل جز مسائل حساس به داده تلقی میشوند. برنامه های حساس به داده به برنامه هایی اطلاق می شود که در آنها تمرکز اصلی مسئله، پردازش حجم عظیمی از داده ها می باشد. در این نوع برنامه ها، انجام کارهای I/O و جابجایی داده ها، بیشتر زمان اجرای برنامه را به خود اختصاص می دهند. پردازش موازی در برنامه های حساس به داده نیز معمولا از طریق تقسیم کردن داده ها به چندین بخش محقق می شود که هر یک از این بخش ها می توانند بطور مستقل پردازش شوند. یک برنامه اجرایی یکسان بطور موازی بروی تمام قسمت های داده ها اجرا می شود، و پس از اجرا، نتایج حاصل از اجرای برنامه ها با یکدیگر ادغام شده و خروجی نهایی را تولید می کند. سکوی هدوپ نیز مطابق با همین روش از تقسیم دادهها و انجام پردازش بروی این دادهها استفاده میکند.
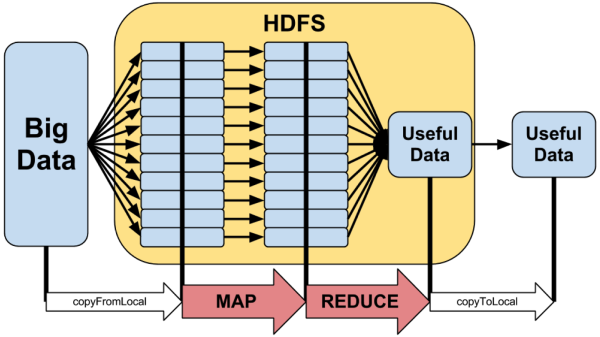
مقیاسپذیری افقی:
مزیت دیگری که پروژه هدوپ از آن برخوردار است، مقیاسپذیری افقی است. در سیستم فایلهای توزیع شده به منظور افزایش و یا کاهش ظرفیت ذخیره سازی میتوان از دو روش مقیاسپذیری استفاده کرد: مقیاسپذیری عمودی و افقی.

در مقیاسپذیری عمودی (scale up)، ظرفیت سختافزاری سیستم را افزایش میدهیم. به بیان دیگر، Ram، CPU و یا دیسک بیشتری را به سیستم موجودتان اضافه میکنید تا آن را قویتر کنید. اما چالشهایی همراه با مقیاسپذیری عمودی وجود دارد:
- همیشه در مورد افزایش ظرفیت سختافزارتان محدودیت وجود دارد. بنابراین، نمیتوانید همواره به افزایش منابع دستگاه ادامه دهید.
- در مقیاسپذیری عمودی، در اکثر مواقع باید ابتدا ماشین را خاموش کرد. سپس برای داشتن مجموعهی سختافزاری هرچه قویتر منابع را افزایش داد و بعد از آن دوباره ماشین را راهاندازی کرد.
در حالت مقیاسپذیری افقی (scale out)، به جای افزایش ظرفیت سختافزار هر دستگاه، به کلاستر موجود گرههای بیشتری اضافه میکنید. و مهمتر از همه این است که میتوانید دستگاههای بیشتری که در حال فعالیت هستند را بدون متوقف کردن سیستم اضافه کنید. بنابراین، در حین مقیاسپذیری افقی هیچ زمانی نیاز نیست به منظور افزایش و یا کاهش مقیاس کلاستر، عملکرد آن را متوقف کرد.
ویژگیهای HDFS
در بخشهای دیگر با تفصیل بیشتری در مورد ویژگیهای هدوپ صحبت خواهیم کرد. اما در حال حاضر، بیایید نگاهی اجمالی بر ویژگیهای HDFS داشته باشیم:
- هزینه: به طور کلی، HDFS میتواند بر روی یک سختافزار ارزان قیمت مانند دسکتاپ/لپتاپ که هر روز از آن استفاده میکنید تا سرورهای ویژه و گران قیمت اجرا شود. بنابراین راه حل بسیار مقرون به صرفهایی برای ذخیرهسازی دادهها در مقیاس بالا است. چون ما از سختافزار مناسب ارزانقیمت استفاده میکنیم، نیازی ندارید که برای مقیاسپذیری افقی کلاستر هدوپ هزینهی زیادی صرف کنید. به بیان دیگر، اضافه کردن گرههای بیشتر به HDFS (مقیاسپذیری افقی) از نظر اقتصادی نسبت به تهیه سختافزار قویتر مقرون به صرفهتر است.
- تنوع و حجم داده: تنوع و حجم دو مورد از ویژگیهای محیط کلان داده می باشند که میتوان براحتی این موارد را در HDFS مدیریت کرد. در HDFS، میتوان دادههای حجیمی مانند چندین ترابایت و یا پتابایت را در انواع مختلف داده ذخیره کرد. بنابراین میتوانید هر نوع دادهای اعم از ساختاریافته، غیرساختاریافته یا نیمهساختاریافته را در آن ذخیره کنید.
- قابلیت اطمینان و مقاومت در برابر خطا: وقتی دادهها را بر روی HDFS ذخیره میکنید، به صورت خودکار دادههای ورودی به بلاکهای دادهای تقسیم میشود و آنها به سبک توزیعشده در کلاستر هدوپ ذخیره میشود. اطلاعات مربوط به اینکه چه بلاک دادهای در کدام گره داده قرار گرفته، بصورت فرادادهای برای آن داده ذخیره میشود. NameNode فرادادهها را مدیریت میکند و DataNodeها مسئول ذخیرهی دادهها هستند. NameNode همچنین مدیریت تکرار دادهها را برعهده دارد. یعنی چندین کپی از دادهها را نگهداری میکند. این تولید مجدد دادهها HDFS را برابر خرابی گره بسیار ایمن میکند. بنابراین، حتی اگر هر کدام گرهها از کار بیفتند، میتوانیم دادهها را از طریق نسخههای دیگر موجود بر سایر گرهها بازیابی کنیم. به صورت پیشفرض، ضریب تکرار 3 است. بنابراین اگر شما 1 گیگابایت فایل در HDFS ذخیره کنید، در نهایت آن 3 گیگابایت از ظرفیت فایل سیستم را اشغال خواهد کرد. NameNode به صورت تناوبی فراداده را بهروزرسانی میکند و ضریب تکرار را ثابت نگه میدارد.
- جامعیت داده: تمامیت داده دربارهی این است که آیا دادهی ذخیرهشده در HDFS من صحیح است یا خیر. HDFS به طور مداوم تمامیت دادههای ذخیرهشده را بر حسب دادهی جمعکنترلی بررسی میکند. اگر هر اشتباهی در صحت دادهها رخ دهد، NameNode از این موضوع اطلاع پیدا میکند. در این حالت، NameNode کپی جدید اضافی ایجاد میکند و کپیهای خراب را حذف میکند.
- توان عملیاتی بالا: توان عملیاتی، مقدار کاری است که در واحد زمان انجام میشود. این ویژگی دربارهی این موضوع است که با چه سرعتی میتوانید به دادههای سیستم دسترسی داشته باشید. به طور کلی، به شما دیدی دربارهی عملکرد سیستم میدهد. همانطور که در مثال بالا مشاهده کردید ما برای بهبود محاسبات جمعاً از 10 گره استفاده کردیم. بنابراین توانستیم وقتی که تمام گرهها به صورت موازی در حال کار بودند، زمان پردازش را بطور چشمگیری کاهش دهیم. در نتیجه، با پردازش دادهها به صورت موازی، زمان پردازش را فوقالعاده کاهش دادیم و بنابراین به توان عملیاتی بالایی رسیدیم.
- محلی بودن محاسبات: این ویژگی مربوط به انتقال پردازش به سمت داده به جای انتقال داده به سمت پردازش است. در سیستمهای سنتی، همیشه داده را به لایه برنامه منتقل میکنیم و سپس آن را پردازش میکنیم. اما در هدوپ، به علت معماری و حجم بالای داده، انتقال داده به لایه برنامه عملکرد شبکه را به حد قابل توجهی کند خواهد کرد و باعث ایجاد گلوگاه در انتقال دادهها خواهد شد. بنابراین، در HDFS، بخش پردازشی را به گرههای داده یعنی جایی که دادهها قرار دارند منتقل میکنیم. بنابراین دادهها را حرکت نمیدهید و برنامه یا واحد پردازش را به محل داده انتقال میدهید.
در آموزشهای بعدی HDFS، به طور عمیق به معماری HDFS میپردازم و به سؤالاتی مانند زیر پاسخ میدهیم:
- وقتی شما در سیستم فایل توزیعشدهی هدوپ دادهای را مینویسید یا آن را بازیابی میکنید، در پشت پرده چه اتفاقی میافتد؟
- چه مکانیسمهایی برای مدیریت تکرار دادهها در سطح یک مرکز داده وجود دارند که HDFS را به یک سیستم مقاوم در برابر خطا تبدیل میکند؟
- سیستم فایل توزیعشدهی هدوپ چگونه از دادهها کپی ایجاد کرده و آنها را مدیریت میکند؟
- کارایی بلاک دادهها چیست؟