
همانطور که در مطلب مربوط به “اکوسیستم هدوپ” صحبت کردیم، آپاچی پیگ یکی از ابزارهای مورد استفاده در اکوسیستم هدوپ است. بطور خلاصه میتوان گفت پیگ یک زبان گردش جریان داده است که به تحلیلگران داده کمک میکند بدون پرداختن به جزیئات برنامهنویسی، بروی منطق برنامه خود تمرکز کنند.در این پست میخواهیم دربارهی این ابزار، معماری آن، مقایسه آن با مدل برنامه نویسی نگاشت/کاهش و الگوهای استفاده از آن صحبت کنیم.
قبل از شروع صحبت در مورد ابزار پیگ، میتوان به این موضوع فکر کرد که در حالی که مدل برنامه نویسی نگاشت/کاهش برای تجزیه و تحلیل دادهها وجود داشت چرا استفاده از آپاچی پیگ میتواند مفید باشد؟ شاید یک پاسخ کوتاه و البته قانع کننده این باشد:
توسعه برنامههای کلان داده بدون نیاز به دانش برنامهنویسی
نوشتن برنامههای نگاشت/کاهش به زبان جاوا نیاز به دانش برنامه نویسی دارد. یک نمونه توسعه یک برنامه ساده با زبان جاوا در “برنامه شمارش کلمات با استفاده از مدل نگاشت/کاهش” آورده شده است. آپاچی پیگ به عنوان ابزاری برای برنامه نویسانی که نمیتوانند با جاوا و پایتون به خوبی کار کنند، پدید آمد. حتی میتوان گفت کسانی که با جاوا و یا پایتون نیز آشنا هستند و توسعه برنامههای نگاشت/کاهش برای آنها دشوار نیست، در برخی موارد آپاچی پیگ را به دلیل سهولت کار ترجیح میدهند. در ادامه نگاهی به این موضوع میاندازیم.
آپاچی پیگ در مقابل نگاشت/کاهش
برنامه نویسان در نوشتن کارهای نگاشت/کاهش به دلیل نیاز به دانش برنامه نویسی جاوا یا پایتون به مشکل بر میخورند. برای آنها، آپاچی پیگ یک راهحل بسیار کارآمد است:
- پیگ لاتین یک زبان گردش داده[1] سطح بالا است، در حالی که نگاشت/کاهش یک مدل توسعه برنامههای پردازش داده سطح پایین است.
- بدون نوشتن کدهای پیچیدهی جاوا برای توسعه منطق برنامههای نگاشت/کاهش، برنامه نویسان میتوانند به راحتی به همان منطق در پیگ لاتین دست یابند.
- آپاچی پیگ از رویکرد چند پرس و جویی استفاده میکند (به عنوان مثال، با استفاده از یک پرس و جو در پیگ لاتین میتوانیم به چندین وظیفه در یک کار نگاشت/کاهش دست یابیم)، که این موضوع تاثیر بسزایی در کمتر شدن تعداد خطوط کد دارد.
- آپاچی پیگ تعداد زیادی عملگرهای از پیش ساخته شده[2] برای پشتیبانی از عملیاتهای دادهایی مانند پیوند[3]، فیلتر[4]، مرتب سازی[5] و غیره فراهم میکند. در حالی که توسعه همان کار در نگاشتکاهش میتواند کار پرهزینهای باشد.
- انجام عملیات پیوند در آپاچی پیگ ساده است. در حالی که اجرای پیوند بین مجموعهی دادهها در نگاشتکاهش دشوار است، از آنجا که مستلزم اجرای پی در پی چندین وظیفهی نگاشت/کاهش برای انجام این کار میباشد.
- علاوه بر این، پیگ انواع ساختار دادههایی مانند تاپلها[6] و کلید/مقدار که در نگاشتکاهش موجود نیست را فراهم میکند. در بخشهای بعدی این نوع از دادهها را با جزئیات بیشتری بررسی میکنیم.
در ادامه به تعریف با جزئیات بیشتر این ابزار و معماری آن میپردازیم.
آپاچی پیگ
آپاچی پیگ سکویی است که برای تجزیه و تحلیل مجموعه دادههای بزرگ که از آنها به عنوان دادههای جریانی یاد میشود، مورد استفاده قرار میگیرد. این سکو به عنوان جایگزینی برای نگاشت/کاهش طراحی شده است، که پیچیدگیهای نوشتن یک برنامهی نگاشت/کاهش را کم میکند. با استفاده از آپاچی پیگ در هدوپ میتوانیم عمل کار بروی دادهها را به راحتی انجام دهیم.
ویژگیهای آپاچی پیگ عبارتند از:
- پیگ برنامه نویسان را بدون دانستن زبان جاوا قادر به نوشتن جریانهای انتقال داده پیچیده میکند.
- آپاچی پیگ دارای دو جزء اصلی میباشد: زبان پیگ لاتین و محیط اجرای پیگ، که در آن برنامههای پیگ لاتین اجرا میشوند.
- در واقع پیگ لاتین یک زبان سادهی جریان داده است که ویژگیهای مشابهی با زبان SQL مانند پیوند، فیلتر، limit و غیره دارد.
- توسعه دهندگانی که با زبانهای برنامه نویسی اسکریپتی و SQL کار میکنند، بدلیل تشابه زبان پیگ لاتین به آنها و سهولت برنامه نویسی، میتوانند براحتی پیگ لاتین را مورد استفاده قرار دهند.
- برنامه نویسان با استفاده از اسکریپت نویسی با زبان پیگ لاتین به تجزیه و تحلیل دادهها و پیادهسازی منطق برنامهی خود میپردازند و این اسکریپتها توسط موتور نگاشت/کاهش موجود در موتور اجرای پیگ تبدیل به تابعهای نگاشت و کاهش میشوند. قبل از پیگ، نوشتن تابعهای نگاشت و کاهش تنها راه پردازش دادهها در اکوسیستم هدوپ بود.
- اگر برنامه نویسان بخواهند توابع دلخواهی خود را که در پیگ موجود نیست بنویسند، استفاده از توابع تعریف شدهی کاربر (UDF[7]) این امکان را برای آنها و در اکثر زبانها مانند جاوا، پایتون، روبی، جایتون، جیروبی و غیره فراهم میآورد. پس از توسعه UDF، میتوان آنها را در اسکریپت نوشته شدهی پیگ در پیگ لاتین جاسازی کرد. در واقع، این موضوع به توسعه پذیری آپاچی پیگ کمک میکند.
- پیگ میتواند انواع دادهها، به عنوان مثال دادههای ساختار یافته، نیمه ساختار یافته یا بدون ساختار را پردازش کند.
- آپاچی پیگ به طور خودکار وظایف را قبل از اجرا بهینه سازی میکند. در این خصوص در ادامه بیشتر صحبت میکنیم.
- درنهایت میتوان گفت استفاده از این ابزار به برنامهنویسان و توسعهدهندگان اجازهی تمرکز بر کل عملیات بدون توجه به تمرکز بروی پیاده سازی برنامه با استفاده از زبانهای سطح پایین را میدهد.
کجا از آپاچی پیگ استفاده کنیم؟
آپاچی پیگ میتواند در موارد زیر مورد استفاده قرار میگیرد:
- مواقعی که به پردازش مجموعه دادههای عظیم مانند وبلاگها، استریم کردن دادههای آنلاین، و غیره نیاز داریم، پیگ میتواند مورد استفاده قرار میگیرد.
- در جاهایی که ما نیاز به پردازش دادهها برای جستجو داریم (لازم است انواع مختلف دادهها پردازش شوند) برای مثال: یاهو برای 40 درصد از فعالیتهای خود از جمله اخبار و موتور جستجو از پیگ استفاده میکند.
- هنگامی که نیاز به پردازش دادههای حساس به زمان را داریم. در این موارد، دادهها سریعاً باید استخراج و مورد تجزیه و تحلیل قرار گیرند. به عنوان مثال، برخی از الگوریتمهای یادگیری ماشین نیاز به دادههای حساس به زمان دارند. برای مثال توییتر که نیازمند استخراج دادهها از فعالیتهای کاربران (توییتها، ریتوییتها و لایکها) و تجزیه و تحلیل دادهها برای پیدا کردن الگوهای رفتاری کاربر و کاوش دانش در این زمینه نظیر توییتهای ترند شده میباشد.
در ادامه به منظور درک بهتر مفاهیم، مطالعهی موردی توییتر را بررسی کنیم.
مطالعه موردی شرکت توییتر
پس از استقبال فراوان از شبکه اجتماعی توییتر، و نرخ رشد بسیار سریع حجم اطلاعات این شبکه، توییتر تصمیم به انتقال دادههای آرشیو به HDFS و انجام کارهای تحلیلی بواسطه هدوپ گرفت.
هدف اصلی توییتر تجزیه و تحلیل دادههای کاربران بود تا به تحلیلهای اشاره شده بر اساس دورههای روزانه، هفتگی و یا ماهانه برسند.
عملیاتهای آماری:
- روزانه چه مقدار درخواست توسط توییتر پاسخ داده میشود؟
- زمان متوسط اجرای درخواست چه میزان است؟
- هر روز در توییتر چند جستجو اتفاق میافتد؟
- چند درخواست منحصر به فرد[8] دریافت میشود؟
- چند کاربر منحصر به فرد در دورههای ذکر شده وجود دارد؟
- توزیع جغرافیایی کاربران چگونه است؟
همبستگی دادههای بزرگ:
- استفاده کاربران تلفن همراه از توییتر چگونه است؟
- تجزیه و تحلیل داده با دسته بندی کاربر، بر اساس رفتار آنها.
- کاربر اغلب از کدام ویژگیها استفاده میکند؟
- اصلاح جستجو و پیشنهادات جستجو.
بررسی در دادههای بزرگ و تولید نتایج بهتر مانند:
- توییتر توانایی تجزیه و تحلیل چه چیزی را در مورد کاربران با استفاده از توییتهای آنها دارد؟
- هر فرد چه کسی را فالو میکند و بر چه اساسی؟
- نسبت دنبال کنندگان به دنبال شوندگان چقدر است؟
- اعتبار یک کاربر چیست؟
بنابراین، برای تجزیه و تحلیل دادهها، توییتر ابتدا از موتور پردازشی نگاشت/کاهش استفاده کرد. به عنوان مثال، آنها میخواستند دریابند که در جدول توییتهای موجود، هر کاربر چند توییت ذخیره کرده است؟
در شکل زیر نحوه استفاده از مدل نگاشت/کاهش برای حل این مسئله آورده شده است:
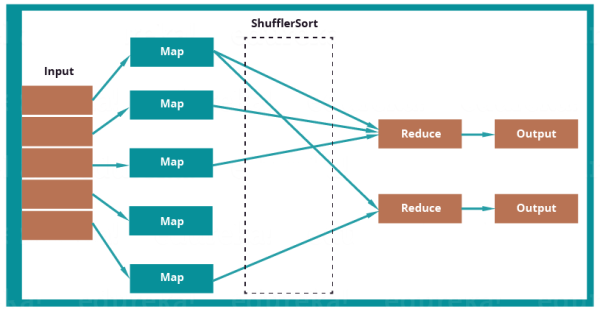
برنامه نگاشت/کاهش در ابتدا اطلاعات جدول توییت را به تابع نگاشت ارسال میکند. تابع نگاشت شناسه کاربری و یک عدد یک را به عنوان کلید مقدار انتخاب میکند. تابع درهمآمیز[9] نیز همه شناسههای کاربری یکسان را با هم دسته بندی میکند. در نهایت، تابع کاهش، مقدار یک مربوط به همهی توییتهای متعلق به یک کاربر را با هم جمع میکند. خروجی، شناسه کاربر، همراه با نام کاربری و تعداد توییتهای هر کاربر خواهد بود.
هنگام استفاده از نگاشت/کاهش، برخی از محدودیتها میتوان متصور شد:
- برنامه تجزیه و تحلیل باید به زبان جاوا و یا پایتون توسعه داده میشد.
- پیوندها، نیز باید به زبان جاوا و یا پایتون نوشته میشدند، که باعث طولانیتر و مستعد خطا شدن آن میشد.
- برای توابع projection و فیلتر، کدهای مورد نظر باید نوشته شود که باعث میشد کل فرایند کندتر پیش رود.
- استفاده از نگاشت/کاهش کار را به مراحل زیادی تقسیم میکند، که مدیریت آن را دشوار میکرد.
بنابراین، توییتر برای تجزیه و تحلیل از آپاچی پیگ استفاده کرد. با استفاده از آن، پیوند مجموعه دادهها، گروه بندی، مرتب سازی و بازیابی آنها آسانتر و سادهتر شده است. شما میتوانید در تصویر زیر ببینید که توییتر چگونه با استفاده از آپاچی پیگ به تجزیه و تحلیل مجموعه دادههای بزرگ خود پرداخته است.
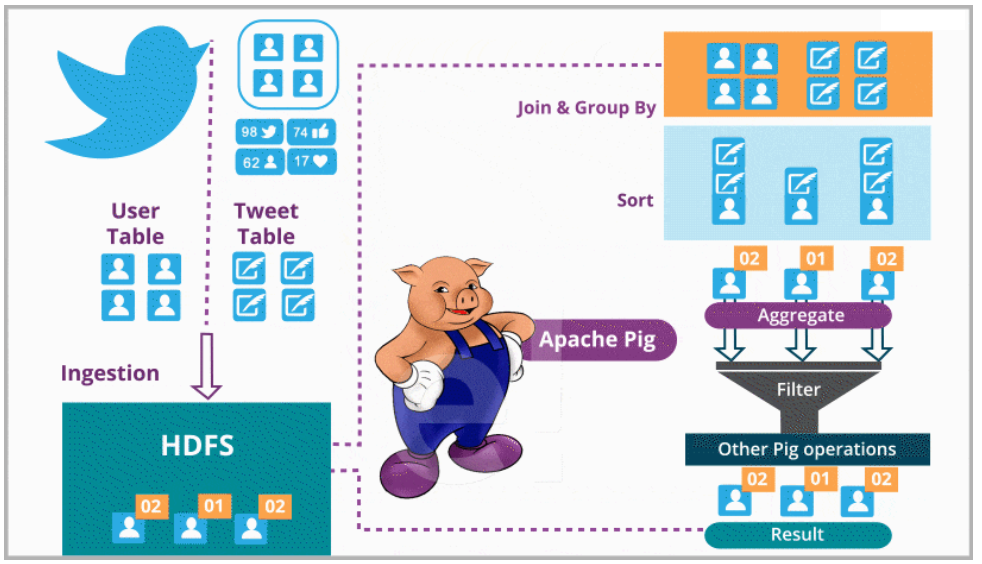
توییتر دارای هر دو دادههای نیمه ساختار یافته (مانند لاگهای سرورهای وب توییتر، لاگهای جستجوهای توییتر، لاگهای جستجوهای MySQL مربوط به توییتر، لاگهای نرم افزارها) و دادههای ساختار یافته مانند توییتها، کاربران، اطلاعیهها، لایکها، ریتوییتها، احراز هویتها، دنبال شوندگان کاربر و غیره است که میتواند به راحتی توسط آپاچی پیگ پردازش شود.
توییتر یک کپی از تمام دادههای خود را در HDFS ذخیره کرد. دو جدول با عناوین دادههای کاربر و دادههای توییت ایجاد کرد. دادههای کاربر شامل اطلاعات در مورد کاربران مانند نام کاربری، دنبال کنندگان، دنبال شوندگان، تعداد توییتها و غیره میشود در حالی که دادههای توییت شامل خود توییت، نویسنده، تعداد ریتوییتها، تعداد لایکها و غیره است. توییتر با استفاده از این دادهها رفتار کاربر خود را تجزیه و تحلیل میکند و تجربههای کاربری آنان را بهبود بخشد.
در ادامه ببینیم که چگونه آپاچی پیگ مسئله مطرح شده مشابه را که توسط نگاشتکاهش حل شد، حل میکند:
تجزیه و تحلیل تعداد توییتهای ذخیره شده توسط هر کاربر، در جداول داده شدهی توییت چگونه است؟
تصویر زیر، رویکرد آپاچی پیگ برای حل این مشکل را نشان میدهد:
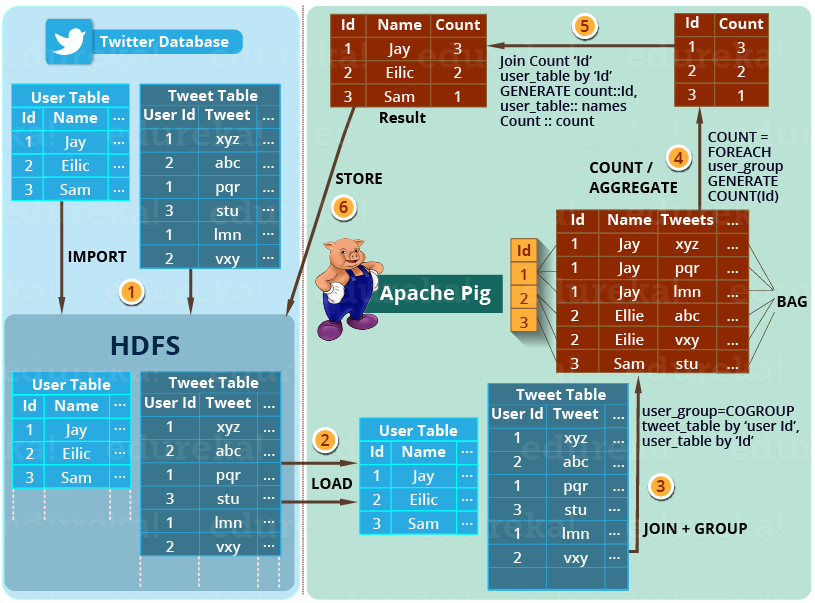
راه حل گام به گام این مسئله در تصویر بالا نشان داده شده است.
گام 1- در ابتدا، توییتر جدولهای توییتری را در HDFS بارگذاری میکند (برای مثال جدول کاربر و جدول توییت)
گام 2- سپس آپاچی پیگ جدولها را در فریم ورک آپاچی پیگ بارگذاری میکند.
گام 3- آنگاه با استفاده از فرمان COGROUP همانطور که در تصویر بالا نشان داده شد، جدولهای توییت و کاربر را پیوند میدهد و آنها را گروه بندی میکند. این عملیات منجر به ایجاد نوع داده درونی Bag میشود (در بخشهای بعدی در مورد آن بحث میکنیم).
(1,{(1,Jay,xyz),(1,Jay,pqr),(1,Jay,lmn)})
(2,{(2,Ellie,abc),(2,Ellie,vxy)})
(3, {(3,Sam,stu)})
گام 4- سپس تعداد توییتهای هر کاربر با استفاده از فرمان COUNT شمارش میشود. بنابراین، تعداد کلی توییتهای هر کاربر به راحتی قابل محاسبه است.
(1, 3)
(2, 2)
(3, 1)
گام 5- در نهایت بین نتیجه بدست آمده و جدول کاربر پیوند انجام میشود تا نام کاربر را با نتیجهی به دست آمده استخراج کند.
(1, Jay, 3)
(2, Ellie, 2)
(3, Sam, 1)
گام 6- در آخر، نتیجه دوباره در HDFS ذخیره میشود.
پیگ تنها به این عملیات محدود نیست. میتواند عملیاتهای مختلف دیگر که قبلاً نیز به آن اشاره شد را انجام دهد. این روشها کمک میکنند تا توییتر تجزیه و تحلیلها و توسعهی الگوریتمهای یادگیری ماشین بر اساس رفتار کاربران و الگوها را انجام دهد.
پس از بررسی مطالعه موردی توییتر، اجازه دهید که درمورد معماری آپاچی پیگ و مدل دادهی پیگ لاتین صحبت کنیم.
معماری آپاچی پیگ
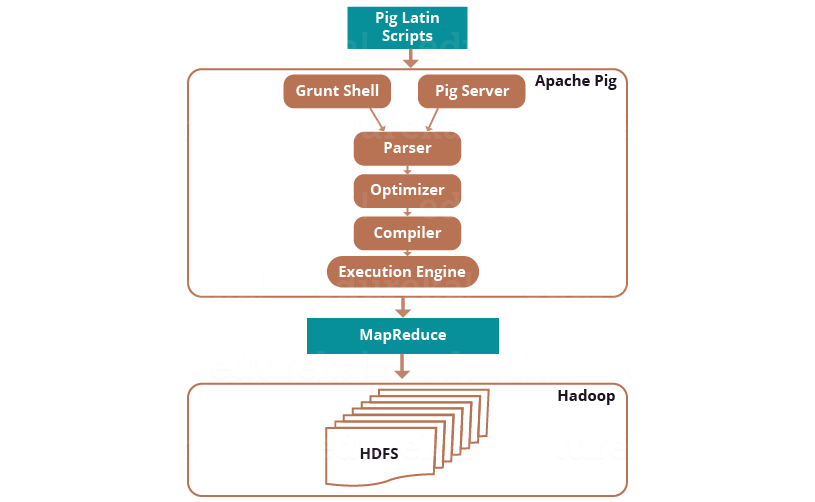
برای نوشتن اسکریپت پیگ، ما به زبان پیگ لاتین و برای اجرای آن نیز ما نیاز به موتور اجرایی پیگ داریم. معماری آپاچی پیگ در تصویر زیر نشان داده شده.
پیگ لاتین
همانطور که در تصویر بالا میبینید، ما اسکریپتهای نوشته شده به زبان پیگ را در موتور اجرایی آپاچی پیگ اجرا میکنیم.
سه راه برای اجرای اسکریپتهای پیگ وجود دارد:
- Grunt Shell: پوستهی تعاملی پیگ که توسط آن میتوان اسکریپتهای پیگ را اجرا کرد.
- فایل اسکریپت: نوشتن دستورات پیگ در یک فایل اسکریپت و اجرای فایل پیگ اسکریپت. این کار توسط سرور پیگ (شکل بالا) انجام میشود.
- اسکریپت جاسازی شده: اگر برخی از توابع در عملگرهای از پیش ساخته شده در دسترس نیست، با استفاده از زبانهای دیگر مانند جاوا، پایتون، روبی، و غیره و توسعه یک توابع تعریف شده توسط کاربر[10] میتاونیم آن توابع را بسازیم و به برنامه خود اضافه کنیم. در واقع تابعهای پیادهسازی شده را در یک فایل اسکریپت پیگ لاتین جا سازی کرد و سپس، آن اسکریپت را اجرا کنیم.
Parser
با بررسی تصویر بالا، متوجه میشوید که اسکریپتهای پیگ پس از عبور از Grunt و یا پیگ سرور، به Parser منتقل میشوند. Parser نوع و نحو[11] اسکریپت را بررسی میکند. Parser یک DAG (گراف مستقیم بدون دور) را در خروجی ارائه میدهد. DAG عملگرهای منطقی و دستورات پیگ لاتین را ارائه میدهد. عملگرهای منطقی به عنوان گرههای گراف و جریانهای داده به عنوان لبههای آن ارائه میشوند.
Optimizer
پس از مرحله Parser، گراف ایجاد شده به Optimizer ارسال میشود. Optimizer فعالیتهای بهینه سازی مانند تقسیم، ادغام، انتقال، و دوباره مرتب کردن عملگرها و غیره را انجام میدهد. Optimizer ویژگیهای بهینه سازی خودکار را به آپاچی پیگ ارائه میدهد و اساساً با هدف کاهش مقدار داده در خط لولهها[12] در هر لحظه از زمان، هنگامی که دادههای استخراج شده را پردازش میکند عمل میکند.
کامپایلر
پس از فرآیند بهینه سازی، کامپایلر کد بهینه سازی را به یک سری از کارهای نگاشت/کاهش کامپایل میکند. کامپایلر بخشی است که به طور خودکار مسئول تبدیل کارهای پیگ به کارهای نگاشت/کاهش میباشد.
موتور اجرایی
در نهایت، همانطور که در شکل معماری آپاچی پیگ نشان داده شد، کارهای نگاشتکاهش برای اجرا به موتور اجرایی ارسال میشوند. سپس کارهای نگاشت/کاهش اجرا و نتیجه لازم حاصل میشود. نتایج را میتوان بر روی صفحه نمایش با استفاده از فرمان “DUMP” مشاهده نمود و میتوان با استفاده از فرمان “STORE” در HDFS ذخیره کرد.
مدل دادهی پیگ لاتین
پیگ انواع دادههای مورد استفاده در اکثر زبانهای برنامه نویسی را پشتیبانی کند. در پیگ لاتین میتوان از هر دو نوع داده، دادههای اولیه مانند (int، float، long، double و غیره) و انواع دادههای پیچیده مانند تاپل، Bag و Map استفاده کرد که در ادامه هریک از آنها توضیح داده خواهند شد. تصویر زیر انواع دادهها و کلاسهای مربوط به پیادهسازی آنها را نشان میدهد:
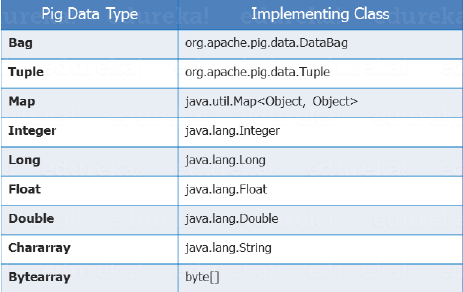
نوع دادهی اسکالر
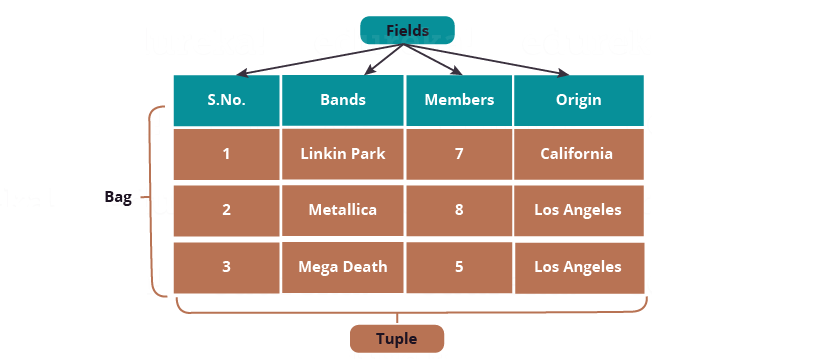
دادههای اسکالر از انواع دادههای پایهی در زبانهای برنامهنویسی هستند که در تمام زبانها استفاده میشوند مانند String، int، float، long، double، char[]، byte[] و غیره. همانطور که در عکس زیر نشان داده شده ارزش هر خانه در یک فیلد یک داده از نوع اسکالر است.
برای فیلدها، اندیسهای مکانی به صورت خودکار توسط سیستم تولید میشوند (که به نام نشانهگذاری مکانی[13] هم شناخته میشود)، که با علامت ‘$’ نشان داده میشود و از $0 شروع میشود، و به صورت $1، $2، و… تولید میشود. در تصویر پایین $0 = S.No. ، $1 = Bands ، $2 = Members و $3 = Origin را نشان میدهند.
همچنین در شکل پایین دادههای اسکالر به صورت “1”، “Linkin Park”، “7”، “California” و غیره هستند.
Tuple
تاپل مجموعهای منظم از فیلدها است که ممکن است هر فیلد از یک نوع دادهای متفاوت باشد. شما میتوانید آن را شبیه به رکوردهای ذخیره شده در جدول پایگاه داده ببینید. همانطور که در تصویر بالا نشان داده شده یک تاپل مجموعهای از خانههای یک سطر است. عناصر یک تاپل لزوماً نیازمند الگو[14] نیستند.
نماد یک تاپل یک جفت پرانتز ‘()’ میباشد. مثالی از تاپل را میتوان (1, Linkin Park, 7, California) فرض کرد.
از آنجایی که عناصر یک تاپل مرتب شده است، میتوانیم به فیلدهای هر تاپل با استفاده از اندیس فیلدها دسترسی داشت، مانند $1 در تاپل بالا که مقدار‘Linkin Park’ را برمیگرداند. ذکر این نکته اهمیت دارد که تاپلها در شکل بالا دارای هیچ الگویی نیستند.
Bag
یک Bag مجموعهای از تاپلها است و این تاپلها زیر مجموعهی ردیفها یا کل سطرهای یک جدول هستند. یک Bag میتواند شامل تاپلهای تکراری باشد و اجباری به منحصر بفرد بودن آنها نیست.
Bag دارای یک الگوی انعطاف پذیر میباشد. به عنوان مثال تاپلهای داخل Bag میتواند تعداد فیلدهای مختلفی داشته باشند. یک Bag همچنین میتواند تاپلهایی با انواع دادههای مختلف داشته باشد. اما برای آنکه آپاچی پیگ به طور مؤثر بتواند Bag را پردازش کند، توصیه میشود فیلدها و انواع دادههای مربوط به تاپلهای آن باید در یک دنباله باشند. Bag با نماد ‘{}’ نشان داده میشود.
{(Linkin Park, 7, California), (Metallica, 8), (Mega Death, Los Angeles)}
{(Metallica, 8, Los Angeles), (Mega Death, 8), (Linkin Park, California)}
دو نوع از Bag، با عنوانهای Outer Bag یا روابط[15] و Inner Bag وجود دارد.
Outer Bag یا روابط چیزی به جز یک Bag از تاپلها نیست. در اینجا Bag های روابط مشابه به رابطها در پایگاه داده هستند. برای درک بهتر به ما اجازه دهید مثالی بزنیم:
{(Linkin Park, California), (Metallica, Los Angeles), (Mega Death, Los Angeles)}
Bag بالا روابط بین گروه و محل شروع آنها را توضیح میدهد.
از سوی دیگر، یک Inner Bag شامل یک Bag در داخل یک تاپل میباشد. برای مثال، اگر ما گروهها را بر اساس محل شروع آنها تاپل بندی کنیم، خواهیم داشت:
(Los Angeles, {(Metallica, Los Angeles), (Mega Death, Los Angeles)})
(California,{(Linkin Park, California)})
در اینجا، اولین فیلد یک رشته است در حالی که نوع فیلد دوم Bag است، که یک Bag درونی در یک تاپل میباشد.

Map
Map شامل یک جفت کلید-مقدار برای نشان دادن عناصر داده است. کلیدها در Map باید از نوع charArray [] و مانند نام ستون منحصر به فرد باشند، بنابراین میتوان آنها را اندیس گذاری کرد و به مقدارهای مرتبط با آن با استفاده از کلید دست پیدا کرد. مقدار نیز، میتواند هر نوع داده باشد. Map با نماد “[]” نشان داده میشود و کلید-مقدار توسط نماد ‘#’ جدا میشوند، همانطور که در تصویر بالا یک Map را مشاهده میکنید.
[band#Linkin Park, members#7], [band#Metallica, members#8]
الگوها در پیگ
الگو، نام فیلد و نوع دادهی آن را مشخص میکند. الگو در پیگ لاتین اختیاری است، اما بدلیلآنکه که بررسی خطا مؤثرتر و تجزیه کردن اسکریپت باعث اجرای کارآمد برنامه میشود، پیگ شما را به استفاده از آنها در صورت امکان تشویق میکند. الگو میتواند توسط هر دو نوع دادهی ساده و پیچیده تعریف شود. در طول تابع بارگذاری، اگر الگو اعلام شده باشد آن نیز به داده متصل میشود.
چند نکته درمورد الگو در آپاچی پیگ:
- در صورتی که الگو تنها شامل نام فیلد است، نوع دادهی فیلد به عنوان آرایهای از بایت در نظر گرفته میشود.
- اگر نامی به فیلد اختصاص داده شود میتوانید توسط نام و شمارهی اندیس فیلد به آن دسترسی داشته باشید، در حالی که اگر نام فیلد موجود نباشد میتوانیم تنها با شمارهی اندیس به آن دسترسی داشته باشید. برای اینکار از نماد $ که به همراه اندیس میآید به مقدار فیلد دسترسی داریم.
- اگر هرگونه عملیاتی که ترکیبی از روابطها است را اجرا کنید (مانند JOIN، COGROUP، و غیره) و اگر هر کدام از روابط دارای الگو نباشند، رابطهی نهایی الگوی Null ارائه خواهد داد.
- در صورتی که الگو Null باشد، پیگ آن را به عنوان آرایهای از بایت در نظر گرفته و نوع دادههای واقعی فیلد را به صورت پویا تعیین خواهد کرد.
در این پست، شما باید اصول اولیه آپاچی پیگ، مدل داده و معماری آن را آشنا شدید. مطالعه موردی توییتر میتواند به شما در برقراری ارتباط بهتر با آن کمک کند. در پستهای بعدی، نصب و راه اندازی آپاچی پیگ و نحوه کار با آن را بررسی خواهیم کرد.
[1] Data Flow
[2] Built-in
[3] Join
[4] Filter
[5] Sort
[6] Tuple
[7] User Defined Functions
[8] Unique
[9] Shuffle
[10] User Defined Function
[11] Syntax
[12] Pipeline
[13] Positional Notation
[14] Schema
[15] Relations