
سازگاری و دسترسپذیر بودن دادهها در سیستمهای توزیعشده از جمله مهمترین چالشهای طراحی یکچنین سیستمهایی میباشد. پایگاهدادههای غیررابطهایی نیز نوعی از سیستمهای توزیعشده محسوب میشوند و ایجاد سازگاری دادهها در بین گرههای یک خوشه پایگاهداده، باعث شده است تا طراحی و نحوه تعامل با این پایگاهدادهها نسبت به پایگاهدادههای رابطهایی متفاوت باشد. در این مقاله قصد داریم تا در مورد سازگاری دادهها، دسترسپذیر بودن آنها و نحوه ایجاد سازگاری در عملیاتهای خواندن و نوشتن دادهها صحبت کنیم. در مقاله قبلی ” ذخیرهسازی کلان دادهها: دورنمایی از پایگاه دادههای NoSQL” به تعریف مفاهیم و مدلهای دادهایی در پایگاهدادههای غیررابطهایی پرداختیم.
تئوری CAP
در طراحی سیستمهای توزیع شده تئوری وجود دارد که بیان میکند در یک سیستم توزیعشده باید از بین سه ویژگی سازگاری داده[1]، در دسترس بودن[2] و تحمل در برار تقسیم خوشه[3] دو مورد را انتخاب کرد. این محدودیت ذاتی سیستمهای توزیع شده، که با نام تئوری CAP یا تئوری بروور[4] شناخته میشود، بیان میکند که غیرممکن است ویژگیهای زیر را در یک سیستم توزیع شده به صورت همزمان داشته باشیم. از آنجاییکه پایگاه دادههای غیررابطهایی نیز نوعی سیستم توزیعشده بحساب میآیند، در نتیجه این تئوری در مورد پایگاه دادههای غیررابطهایی نیز صدق میکند. به منظور درک بهتر این تئوری هریک از این ویژگیها را تعریف میکنیم:
سازگاری: اگر این ویژگی برقرار شود، تضمین میشود که در زمان خواندن دادهها از پایگاه داده بروزترین داده در اختیار کاربر قرار بگیرد و یا سیستم خطایی مبنی بر نقض سازگاری ارسال میکند.
در دسترس بودن: برقرار بودن این ویژگی بیان میکند که سیستم در درصورت وجود پاسخ حتما آن را به عنوان پاسخ پرسوجو ارسال میکند. اگرچه ممکن است این پاسخ بروزترین داده در پایگاه داده نباشد.
تحمل در برابر تقسیم خوشه: اگر سیستم دارای این ویژگی باشد، حتی با وجود شکست در برخی از قسمتهای شبکه (و تقسیم شدن خوشه به چندین قسمت مجزا) بتواند به کار خود ادامه دهد.
در سال 2000 میلادی، اریک بروور این فرضیۀ را مطرح کرد، که در هر زمان تنها دو مورد از سه مشخصۀ گفته شده قابل تضمین در یک سیستم توزیعشده است. چند سال بعد، گیلبرت و لینچ[5] این فرضیه را به صورت رسمی و مدون بیان کردند، و نتیجه گرفتند که در هر سیستم توزیع شده تنها دستیابی به یکی از ترکیبهای زیر ممکن است: AP (در دسترس بودن و تحمل در برابر تقسیم خوشه)، CP (سازگاری و تحمل در برابر تقسیم خوشه) یا AC (در دسترس بودن و سازگاری). جدول زیر، برخی از پایگاه دادههای غیررابطهایی را براساس هریک از این سه دسته نشان میدهد.
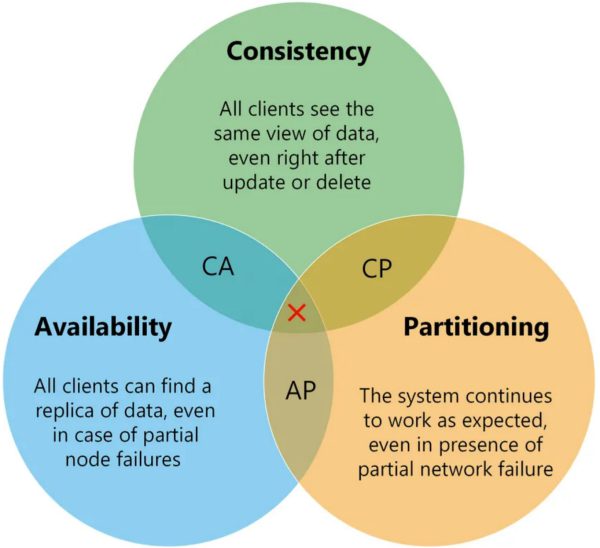
در هر گروه، پایگاهدادهها براساس ویژگیهای تئوری CAP ، مجدداً طبقهبندی میشوند. همانطور که نشان داده شده است، بیشتر پایگاهدادههای بررسی شده در گروههای «AP» و «CP» دستهبندی میشوند. زیرا فراهم نکردن P (تحمل در برابر تقسیم خوشه) در سیستمهای توزیع شده تنها با این فرض ممکن است، که شبکۀ زیرساخت هیچگاه دچار خرابی نشده و اتصال قطع نخواهد شد، که در عمل در سیستمهای توزیع شده این امر با تقریب بسیار بالایی غیرممکن است. برخی از پایگاهدادهها، نظیر MongoDB، میتوانند به گونهای پیکربندی شوند که فراهم کردن کامل ویژگی سازگاری را با فدا کردن مقداری از دسترس پذیری و یا eventual consistency را با فراهم کردن دسترسیپذیری بالا تضمین کنند؛ به همین منظور در هر دو ستون AP و CP مشاهده میشوند.
|
الگوی داده |
AP | CP |
AC |
|
کلید/مقدار |
Riak, Infinispan, Redis, Voldemort, Hazelcast | Infinispan, Membase/CouchBase, BerkeleyDB |
Infinispan |
|
سطر گسترده |
Cassandra |
HBase, Hypertable | – |
| سندگرا | MongoDB, RavenDB, CouchDB, Terrastore | MongoDB |
– |
|
گرافی |
Neo4J, HypergraphDB, BigData, AllegroGraph, InfoGrid, InfiniteGraph | InfiniteGraph | – |
البته پس از چندین سال تئوری جدیدتری نسبت به تئوری CAP با عنوان تئوری PACELC مطرح شد که این تئوری عنوان میکند اگر سیستم دچار هیچگونه نقصی نشد (خوشه بصورت نرمال بکار خود ادامه دهد و هیچگونه شکستی آن را به دو یا چند قسمت تقسیم نکند) نیز باید بین تاخیر پاسخ و سازگاری دادهها یکی را انتخاب کنیم و در واقع موازنهایی بین این دو فاکتور برقرار کنیم. در مقاله دیگری با تفصیل بیشتر در این مورد و بطور کلی اصول طراحی سیستمهای توزیع شده صحبت خواهیم کرد.
ویژگیهای ACID و BASE
در سال 1970 میلادی، جیم گری[6] مفهوم تراکنش[7] را که به معنی واحد کاری در یک سیستم پایگاه داده است، ارائه کرد. یک تراکنش باید چهار ویژگی اصلی را دارا باشد: تجزیهناپذیری[8]، سازگاری[9]، ایزوله بودن[10] و پایایی[11]. این ویژگیها، که با سرواژه [12]ACID شناخته میشوند، طراحی سیستمهای پایگاه داده را پیچیده میکنند؛ و این پیچیدگی در سیستمهای پایگاه داده توزیع شده، که داده در بخشهای مختلفی داخل یک شبکۀ کامپیوتری پخش میشوند، بیشتر خواهد بود. با این حال، این خصیصه، با تضمین اینکه هر عملیات، سازگاری در پایگاه داده را حفظ میکند، کار توسعهدهندگان را ساده میکند. همچنین به دلیل آنکه عملیاتها ذاتاً مستعد شکست و ایجاد تأخیر در شبکه هستند و به منظور تضمین موفقیت تراکنش، پیشبینیهای فوقالعادهای باید در نظر گرفته شود.
در سالهای اخیر، سیستمهای مدیریت پایگاهدادههای رابطهای[13] توزیع شده، به منظور حفظ سازگاری دادهها در طول پارتیشنها، امکان اجرای تراکنشها به وسیلۀ پروتکلهای خاص را فراهم کردهاند. نمونهای از این RDBMSها، مگااستور[14] است، پایگاهدادهای توزیع شده که قابلیت پشتیبانی از تراکنشهای ACID در جداولی خاص و پشتیبانی محدود تراکنشها در جداول داده مختلف را داراست.
مگااستور توسط BigTable پشتیبانی میشود؛ اما برخلاف BigTable، برای پشتیبانی از روابط سلسلهای در بین جداول، از یک زبان اسکیما استفاده میکند و مدلی نیمهرابطهای را فراهم میکند. با اینکه مگااستور (در مقایسه با استفادۀ مستقیم از BigTable) کارآیی خوبی نداشت، در بسیاری از کاربردها، نیاز به سادگی اسکیما و تضمین همگامسازی رونوشتها[15] احساس میشد. مانند بسیاری از پایگاههای داده، رونوشتها در مگااستور توسط نسخهای از الگوریتمPaxos همگام میشوند.
یکی از پروتکلهای رایج برای اجرای تراکنشها در محیطهای توزیع شده در این سیستمها، 2PC (پروتکل تثبیت دو مرحلهای[16]) است. این پروتکل حتی در سرویسهای وب نیز رواج یافته، و استفاده از تراکنشها را حتی در معماریهای مبتنی بر REST نیز ممکن ساخته است. پروتکل 2PC، از دو بخش اصلی تشکیل شده است:
- مرحلهای که مولفه هماهنگکننده[17]، از پایگاهدادههایی که درگیر تراکنش هست درخواست عملیات پیش تثبیت [18] را میکند. اگر تمام پایگاهدادهها تمام عملیاتها را به اتمام برسانند، مرحلۀ 2 صورت میگیرد. در غیر این صورت، حتی اگر یکی از پایگاهدادهها تراکنش را نپذیرند (یا نتوانند پاسخ دهد)، تمامی پایگاهدادهها تغییرات صورت گرفته را بازگردانی میکنند[19].
- هماهنگکننده از پایگاهدادهها درخواست اجرا عملیات تثبیت را میکند. اگر هرکدام از پایگاهدادهها عملیات تثبیت را رد کنند، بازگردانی در تمام پایگاهدادهها اجرا میشود.
براساس تئوری CAP، استفاده از پروتکلی مانند 2PC (برای مثال در سیستم CP) اثرات منفی روی دسترسپذیری سیستم خواهد داشت. به این معنی که اگر پایگاهدادهای شکست بخورد (برای مثال، به دلیل عملکرد نادرست سختافزاری)، تمام تراکنشهای اجرا شده در بازه خرابی شکست خواهد خورد. به منظور اندازهگیری شدت این تأثیر، در دسترس بودن هر عملکرد میتواند به عنوان حاصل در دسترس بودن اجزای منفرد درگیر در این عملیات محاسبه شوند. برای مثال، اگر هر پارتیشن پایگاهداده 99.9% در دسترس باشد، یعنی 43 دقیقه در هر ماه میتواند در دسترس نباشد، اجرا تثبیت با استفاده از پروتکل 2PC بر 2 پارتیشن در دسترس بودن را به 99.8% کاهش میدهد، یعنی 86 دقیقه در ماه خارج از دسترس بودن.
علاوه بر این، 2PC پروتکلی مصدود کننده است، به این معنی که پایگاهدادههای درگیر در یک تراکنش هنگام روند اجرا تثبیت به صورت موازی قابل استفاده نیستند. در نتیجه، با افزایش تعداد تراکنشهای همزمان، تأخیر سیستم بیشتر خواهد شد. به همین دلیل، در بسیاری از رویکردهای پایگاهدادههای NoSQL، تصمیم گرفته شد که محدودیتهای سازگاری کاهش داده شوند. این رویکردها با نام [20]BASE شناخته میشوند. ایده پیادهسازی این مفهوم در سیستمها این است که، به جای شکست کل سیستم، اجازه دهد بخشی از سیستم دچار شکست شود؛ که منجر به دسترسی بیشتر سیستم خواهد شد.
طراحی سیستمهای BASE، و پایگاهدادههای NoSQL مبتنی بر BASE به صورت خاص، اجرای عملکردهای مشخصی را که رونوشتها (کپیهایی از دادهها) را در حالت ناسازگار قرار میدهند، مجاز میدانند. همانطور که از نام آن بر میآید، سیستمهای BASE، با معرفی به اصطلاح حالت نرم[21] رونوشت، دسترسی پذیری سیستم را در اولویت قرار میدهند، یعنی هر پارتیشن ممکن است دچار شکست شود و به کمک رونوشتها بازسازی شود. از طرفی، این سیستمها مکانیزمی نیز برای همگامسازی رونوشتها تعبیه کردهاند. این مکانیزم با عنوان Eventual Consistency شناخته میشود، تکنیکی که بر اساس برخی معیارهایی سیستم را به حالت سازگار برمیگرداند و ناسازگاریها را حل میکند. اگرچه Eventual Consistency تضمین نمیکند که کاربر در هنگام خواندن دقیقاً مقدار مشابهای از تمام رونوشتها را دریافت کند، اما با توجه به نوع کاربرد از پایگاهدادهها، وجود این درخواستهای خواندن در بسیاری از کاربردها قابل قبول است. برای مثال پایگاهداده Cassandra در پایگاهدادههای NoSQL، سیاستهای زیر را درجهت بروزرسانی رونوشتها پیادهسازی میکند:
اصلاح در هنگام خواندن[22]: ناسازگاریها در طول خواندن داده اصلاح میشوند. به این معنی که نوشتن داده ممکن است ناسازگاریهایی برجای بگذارد، که تنها بعد از عملیات خواندن برطرف خواهد شد. در این روند، مولفه دریافتکننده، داده را از مجموعهای از رو نوشتها میخواند و اگر مقادیر ناسازگار بیابد، موظف است که رونوشتهایی که دادههای قدیمی دارند را بروز رسانی کند. قابل توجه است که تضاد در رونوشتها فقط زمانی رفع خواهد شد که دادهها درگیر عملیات خواندن باشند.
اصلاح در زمان نوشتن[23]: زمانی که دادهها(رونوشتها) بر روی مجموعهای از گرهها نوشته میشود، ممکن است تعدادی از گرهها در دسترس مولفه هماهنگکننده نباشند. با استفاده از این سیاست، بهروزرسانیها برای زمانیکه گرهها در دسترس باشند زمانبندی میشوند تا اجرا شوند.
اصلاح ناهمگام[24]: تصحیح کردن نه بخشی از عملیات نوشتن و نه عملیات خواندن است، همگامسازی میتواند با گذشت زمان از آخرین به روزرسانی، مقدار عملیاتهای نوشتن یا رخدادهای دیگری که نشان میدهد پایگاه داده در حالت سازگار نیست، آغاز شود.
علاوه بر سازگاری در عملیاتهای خواندن و نوشتن، در سیستمهای ذخیرهسازی توزیع شده مفهوم پایایی[25] بهوجود میآید، که توانایی یک سیستم در ماندگاری دادهها حتی با وجود شکستها است. به همین دلیل پیش از نمایش پیغام موفقیت عملیات به کاربر، دادهها بر روی تعدادی حافظۀ غیرفرار نوشته میشود. در سیستمهای Eventually Consistent ، مکانیزمهایی برای درجهبندی پایایی و سازگاری سیستم وجود دارد. در ادامه، این مفاهیم را با کمک یک مثال روشن میکنیم. فرض کنید N تعداد گرههایی است که کلیدی بر روی آنها رونوشت شده است، W تعداد گرههایی که برای موفق خواندن عمل نوشتن مورد نیاز باشد، و R تعداد گرههایی باشد که عملیات خواندن روی آنها اجرا میشود. جدول پایین پیکربندیهای مختلف برای W و R و همچنین نتایج اعمال این پیکربندیها را نشان میدهد. هر مقدار به تعداد رونوشتهایی که برای تأیید موفقیت عملیات لازم است اشاره دارد.
سازگاری قوی[26] با اجرای W+R > N اتفاق میافتد؛ یعنی مجموعۀ گرههای درگیر در عملیاتهای خواندن و نوشتن طوری همپوشانی دارند که همیشه عملیاتهای خواندن آخرین نسخه از داده را به دست میآورند. معمولاً RDBMsها شرط W=N را دارند؛ تمام رونوشتها ماندگار هستند و همچنین دارای شرط R=1 هستند چون در هر عملیات خواندن، دادههای بروز را بازمیگرداند. سازگاری ضعیف[27] زمانی به وجود میآید که W+R≤N برقرار میشود. در این شرایط عملیاتهای خواندن ممکن است دادههای قدیمی دریافت کنند. Eventual Consistency، مورد خاصی از سازگاری ضعیف است که در آن تضمین میشود، اگر دادهای بر روی سیستم نوشته میشود، نهایتاً به تمام رونوشتها فرستاده خواهد شد. این موضوع بستگی به تأخیر شبکه، تعداد رونوشتها و بار سیستم و معیارهای دیگری دارد.
اگر نیاز باشد عملیاتهای نوشتن سریعتر صورت بگیرد، میتوان با قبول پایایی کمتر، روی یک یا مجموعهای کمتر از گرهها انجام شوند. اگر W=0 باشد، کاربر نوشتن سریع، اما با کمترین پایایی ممکن را تجربه میکند، زیرا هیچ تأییدیهای مبنی بر موفقیت آمیز بودن عملیات نوشتن وجود ندارد. اگر W=1، دادهها حداقل باید دریک گره نوشته شوند تا موفقیت آمیز بودن عملیات نوشتن به کاربر بازگردانده شود، و در نتیجه پایایی را به نسبت W=0 بهبود میبخشد. به صورت مشابه میتوان عملیات خواندن را بهینه ساخت. انتخاب R=0 به عنوان یک گزینه مطرح نیست. برای دستیابی به مقدار بهینه برای خواندن، میتوان از R=1 استفاده کرد. در بعضی مواقع (مثل استفاده از سیاست اصلاح در زمان خواندن)، ممکن است ملزم به خواندن از تمام گرهها باشیم، یعنی R=N، و با وجود کاهش سرعت عملیات، نسخههای متفاوت داده را ادغام کنیم. طرحی میانه برای نوشتن یا خواندن، قاعده حدنصاب[28] میباشد، به این صورت که عملیات (خواندن یا نوشتن) روی زیرمجموعهای از گرهها انجام میشود. معمولاً، مقدار استفاده شده در قاعده حدنصاب N/2 + 1 است، به طوری که 2 نوشتن یا خواندن متوالی حداقل در یک گره مشترک باشند.
|
مقدار |
نوشتن (W) | خواندن (R) |
|
0 |
انتظار هیچ تأییدیهای از هیچ گرهای نداریم (امکان شکست وجود دارد) | بدون کاربرد |
|
1 |
یک تأییدیۀ واحد کافی است (حالت بهینه در نوشتن) | خواندن از طریق یکی از رونوشتها انجام میگیرد (حالت بهینۀ خواندن) |
|
M(حدنصاب)، M<N |
انتظار تأییدیۀ از تعدادی از رونوشتها را داریم | خواندن از طریق مجموعهای از رونوشتها انجام میگیرد (ممکن است نیاز به رفع اختلافات سمت کاربر باشد) |
|
N (تمام گرهها) |
انتظار تأییدیه از تمام رونوشتها را داریم (دسترسی کاهش مییابد، اما پایایی افزایش پیدا میکند) | خواندن از طریق تمام رونوشتها صورت میگیرد که باعث افزایش تأخیر عملیات خواندن میشود |
در پایان به این نکته نیز اشاره کنیم که در پایگاه دادههای غیررابطهای علاوه بر توجه به ملاحظات سازگاری و دسترسپذیری دادهها، نوع مدل دادهایی که یک پایگاه داده پشتیبانی میکند نیز بسیار اهمیت دارد و در تصمیمگیری انتخاب یک ابزار مناسب برای ذخیره دادهها نقش بسزایی دارد. در مقالههای بعدی در مورد هر یک از مدلهای دادهای، با معرفی معماری پایگاه دادههای مطرح در هر گروه، صحبت خواهیم کرد.
[1] Consistency
[2] Availability
[3] Partition tolerance
[4] Brewer’s
[5] Gilbert and Lynch
[6] Jim Gray
[7] Transaction
[8] Atomic
[9] Consistency
[10] Isolation
[11] Durability
[12] (ACID (Atomicity, Consistency, Isolation, Durability
[13] RDBMS
[14] Megastore
[15] Replica Synchronization
[16] 2phase Commit Protocol
[17] coordinator component
[18] Precommit
[19] Rollback
[20] (BASE (Basically Available, Soft State, Eventually Consistent
[21] soft state
[22] Read-repair
[23] Write-repair
[24] Asynchronous-repair
[25] Durability
[26] Strong Consistency
[27] Weak Consistency
[28] Quorum